[허수아비] 람다(Lambda) vs 카파(Kappa) 아키텍처: 데이터 파이프라인 설계기
CCTV 기반 조류 충돌 예방 시스템 '허수아비'에서 실시간 경보와 장기 통계를 동시에 충족하기 위해, Lambda 아키텍처를 검토하고 최종적으로 Spark 중심의 하이브리드 Kappa 아키텍처를 선택한 설계 과정과 근거를 공유합니다.
‘허수아비’ 프로젝트의 팀장이자 인프라 담당을 맡게 되었습니다. 시스템 아키텍처를 설계함에 있어서 두 가지 상반된 요구사항을 동시에 충족하는 것이었습니다. CCTV와 레이더로 들어오는 영상에서 조류를 탐지(YOLOv8)하여 즉각적인 실시간 경보를 울리는 동시에, 축적된 데이터로 장기적인 통계적 위험도를 분석해야 합니다.
여기에 AWS EC2 2대라는 인프라 제약과 Hadoop(HDFS) 필수 활용이라는 기획 조건이 더해졌습니다. 이 글에서는 초기 Lambda 아키텍처를 구상했다가 최종적으로 Kappa 아키텍처로 선회한 고민의 과정과, 완성된 시스템의 시퀀스 다이어그램을 정리합니다.
미리보기
- Lambda 기각 이유: 코드베이스 이원화(실시간/배치 로직 2벌)와 오버엔지니어링 우려
- Kappa 채택 근거: Spark Structured Streaming 하나로 실시간 경보와 윈도우 통계를 단일 처리
- Hadoop 역할 재정의: 연산 엔진이 아닌, 원시 로그를 장기 보존하는 Cold Storage로 축소
- 최종 구조: Kafka → Spark(Speed + Stats + Archive 병렬 처리) → DB / HDFS / 재발행 토픽
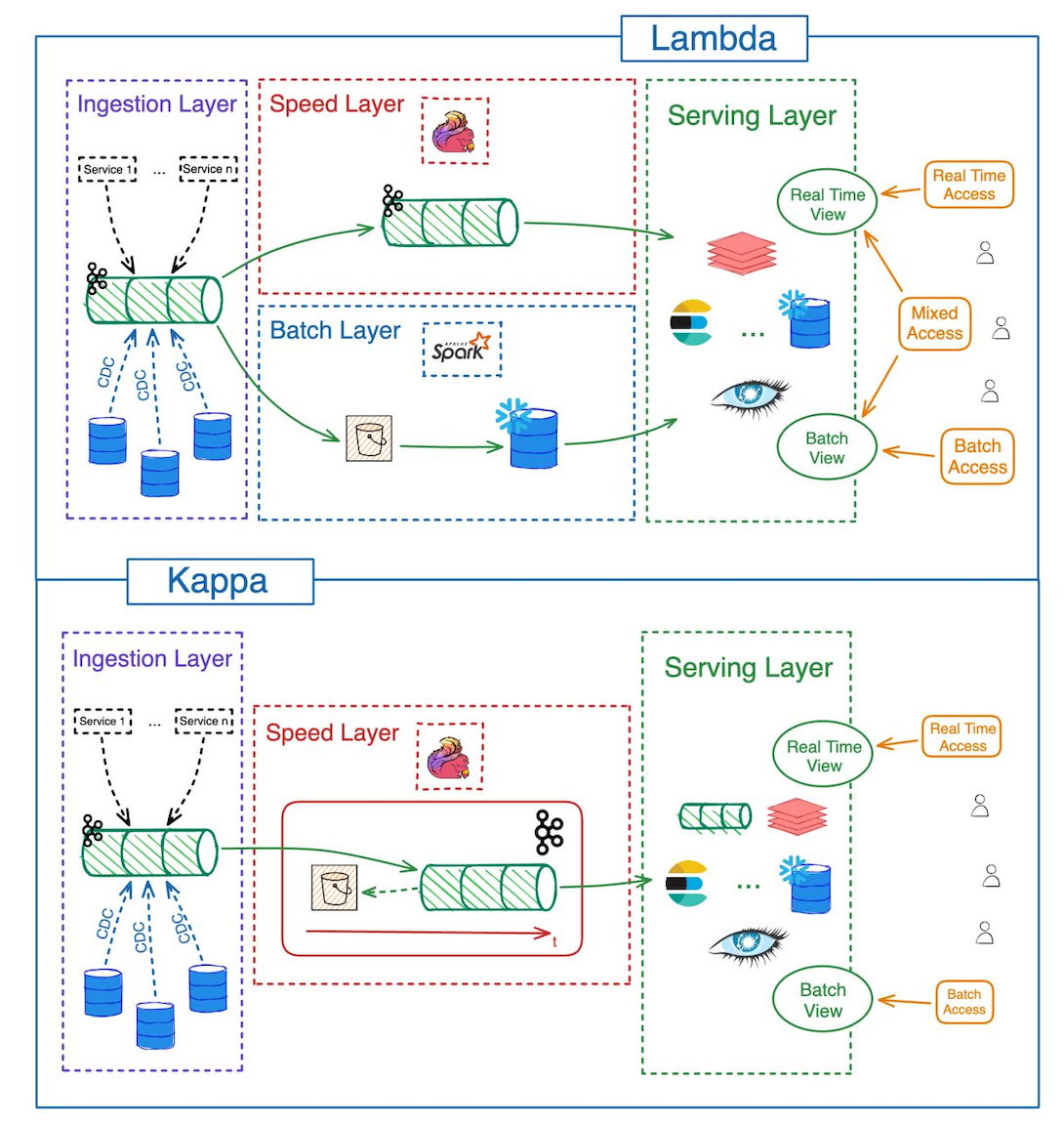
1. 빅데이터의 정석, Lambda 아키텍처
실시간 처리와 장기 데이터 분석을 동시에 다뤄야 할 때 가장 먼저 떠오르는 표준은 Lambda 아키텍처입니다.
Lambda 아키텍처는 데이터가 유입되면 두 갈래로 나눕니다.
- Speed Layer: AI가 탐지한 위험 객체를 Kafka를 통해 즉시 받아, 관제 대시보드(WebSocket)에 지연 없이 알림을 전달합니다.
- Batch Layer: 탐지 로그, 레이더 데이터, 기상청 API 데이터를 Hadoop(HDFS)에 영구 저장하고, Spark Batch Job으로 주기적(일/주/월 단위)인 대용량 집계를 수행합니다.
Lambda를 망설이게 한 Pain Points
이론적으로는 가장 완벽하고 견고한 아키텍처입니다. 하지만 인프라 설계 단계에서 현실적인 벽에 부딪혔습니다.
- 코드베이스 이원화: 실시간 알림 판단 로직과 배치 통계 로직을 별개로 개발·유지해야 합니다. 제한된 개발 기간에 두 벌의 코드를 관리하는 것은 큰 부담이었습니다.
- 오버엔지니어링: AI가 분석을 마치고 Kafka로 전송하는 ‘탐지 로그’(텍스트 JSON)와 기상청 데이터는 용량이 매우 작습니다. 이 소규모 데이터를 조인하기 위해 무거운 Hadoop/Spark 배치 생태계를 풀가동하는 것은 자원 낭비였습니다.
2. 모든 것은 스트림이다, Kappa 아키텍처
Lambda의 복잡성을 해결하기 위해 눈을 돌린 곳은 Kappa 아키텍처였습니다.
Kappa 아키텍처의 핵심 철학은 “Batch Layer를 없애고, 모든 데이터를 끊임없이 흐르는 Stream으로 통합하여 처리한다”는 것입니다.
- 단일화된 코드베이스: Spark Structured Streaming 하나만 띄웁니다. Kafka로 들어오는 데이터를 실시간으로 읽으면서, “위험 구역 침범 시 즉시 알림”이라는 Speed 처리와 “1분/1시간 윈도우 단위 출현 빈도 집계”라는 통계 처리를 하나의 로직 안에서 동시에 수행합니다.
- Hadoop의 역할 재정의 (Hybrid Kappa): EC2 디스크 용량 한계 때문에 Kafka에 모든 데이터를 장기 보관할 수 없었습니다. 기획 필수 요건이었던 Hadoop(HDFS)을 연산 엔진이 아닌, 원시 로그(Raw Data)를 1년 이상 장기 보존하는 수동적인 Cold Storage로 역할을 축소시켰습니다.
결과적으로 개발 편의성을 극대화하면서 분산 처리(Spark)의 강점을 살리고 인프라 부담을 줄이는 Spark 중심의 하이브리드 Kappa 아키텍처가 탄생했습니다.
3. Lambda vs Kappa
 lambda vs kappa
lambda vs kappa
프로젝트의 제약 조건과 데이터 특성을 기준으로 두 아키텍처를 비교 분석한 결과입니다.
| 비교 항목 | Lambda 아키텍처 | Kappa 아키텍처 |
|---|---|---|
| 핵심 구조 | Speed Layer와 Batch Layer 분리 | Stream 단일 레이어로 통합 |
| 코드 유지보수 | 복잡 (실시간용·배치용 코드 2벌) | 단순 (Spark Streaming 코드 1벌) |
| 분산 처리 엔진 | Spark Streaming + Spark Batch | Spark Structured Streaming (통합) |
| Hadoop의 역할 | 데이터를 조인·집계하는 핵심 연산 무대 | 원시 데이터(Raw)를 덤프하는 Cold Storage |
| 백엔드(Spring) 부하 | 알림 전달과 통계 조회를 각각 처리 | Kafka(알림)와 DB(통계)만 바라보는 얇은 중계자 |
| 적합한 환경 | 초거대 용량 데이터, 높은 무결성이 필요한 곳 | 빠른 개발, 소규모 로그의 실시간 집계가 중요한 곳 |
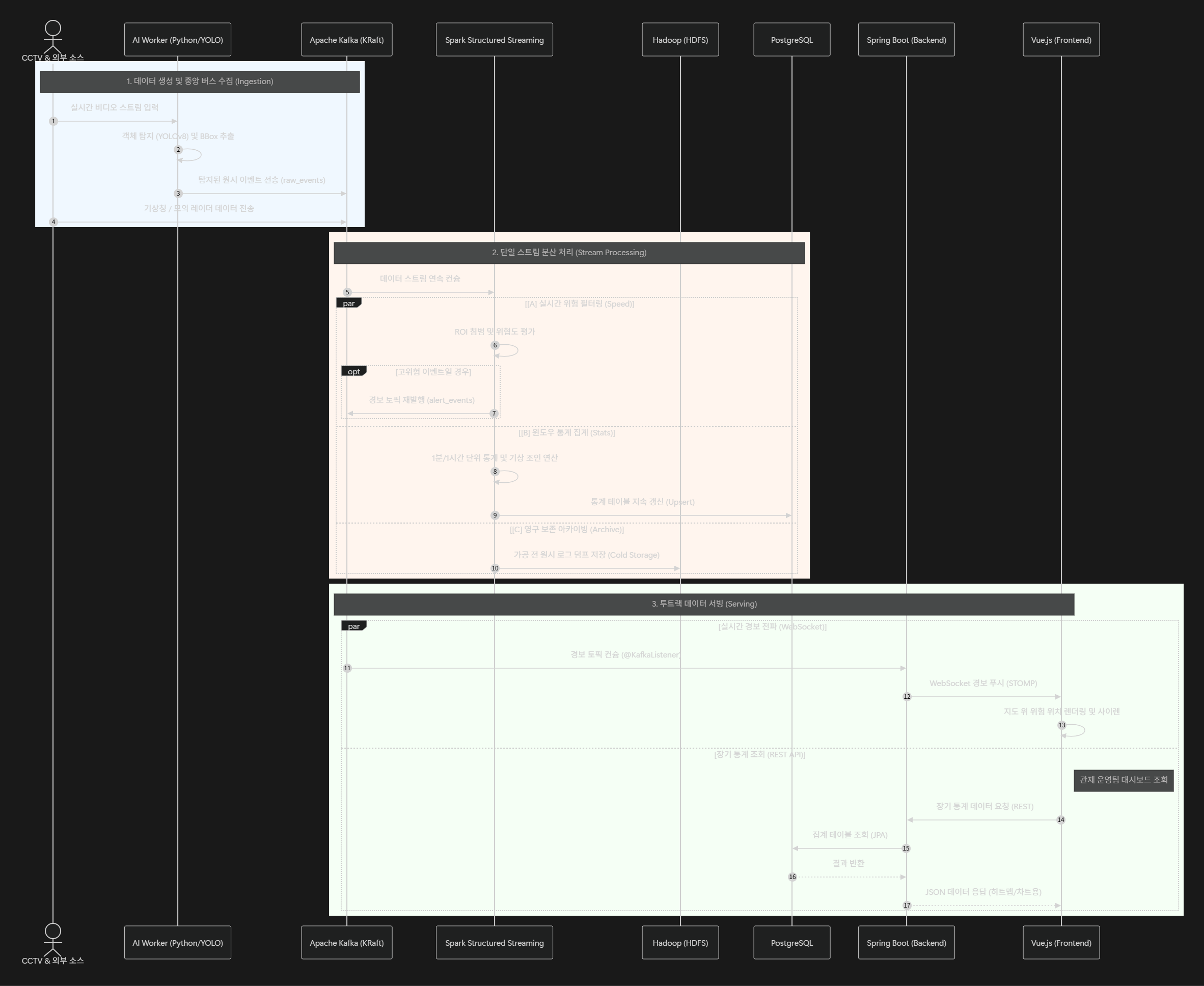
4. 최종 아키텍처 데이터 흐름
Spring Boot와 Vue.js를 서빙 레이어로, Kafka와 Spark가 데이터를 통제하는 Kappa 아키텍처의 최종 시퀀스 다이어그램입니다.
Spark Structured Streaming으로 스트림 처리를 단일화하고, Spring Boot는 비즈니스 로직과 API 서빙에 집중하도록 결합도를 낮췄습니다.
 sequence diagram
sequence diagram
부록
A. 브로커 비교: Apache Kafka vs Redis
- 공통점: 생산자(Producer)가 메시지를 넣고 소비자(Consumer)가 꺼내가는 중간 버퍼 역할을 합니다.
- 차이점 (영속성): Redis는 메모리(RAM) 기반이라 속도가 빠르지만, 소비자가 메시지를 꺼내면 데이터가 휘발됩니다(Pub/Sub 기준). 반면 Kafka는 디스크에 데이터를 차곡차곡 쌓아두는 ‘분산 로그 시스템’입니다. 소비자가 읽어가도 설정된 기간(예: 7일) 동안 데이터가 보존됩니다. 이 차이 덕분에 Kappa 아키텍처에서 과거 데이터를 다시 꺼내어 재처리(Replay)하는 것이 가능합니다.
B. 처리기 비교: Apache Spark vs Celery Worker
- 공통점: 브로커에서 데이터를 꺼내와, 메인 서버를 대신해 무거운 비동기 백그라운드 작업을 수행합니다.
- 차이점 (작업 단위): Celery는 ‘이메일 전송’, ‘이미지 리사이징’처럼 독립적인 개별 작업(Task) 처리에 특화되어 있습니다. 반면 Spark는 끊임없이 쏟아지는 스트림 데이터를 1분/1시간 윈도우로 묶어 그룹화·조인·집계하는 대규모 데이터 연산(Data Processing)에 특화된 분산 엔진입니다.
C. 배치(Batch) vs 스트림(Stream)
배치 처리 = 양동이에 물 모아서 한 번에 붓기
데이터가 양동이에 가득 찰 때까지 기다렸다가 특정 시점에 한꺼번에 처리합니다. 처리해야 할 데이터의 ‘시작과 끝’이 정해져 있어 대용량을 안정적으로 처리할 수 있지만, 결과가 나올 때까지 기다려야 합니다.
스트림 처리 = 흐르는 수돗물 바로 마시기
데이터가 한 방울씩 들어올 때마다 즉시 처리합니다. 데이터의 ‘끝’이 없으며, 24시간 365일 무한히 들어오는 연속적인 이벤트 흐름 그 자체를 다룹니다.
허수아비 시스템의 핵심 입력값들(CCTV 탐지 로그, 레이더 좌표)은 태생부터 완벽한 스트림 데이터입니다. Kappa 아키텍처는 통계 연산조차 이 흐르는 물 위에서 바로 계산합니다. 파이프라인 중간에 ‘1분’, ‘1시간’ 단위의 윈도우(거름망)를 설치해, 배치 처리를 위해 자정까지 기다릴 필요 없이 거의 실시간으로 최신화된 통계를 대시보드에서 확인할 수 있게 됩니다.
마치며
초기에는 Lambda 아키텍처를 정답으로 생각했습니다. 하지만 EC2 2대라는 인프라 한계와 개발 기간을 고려하면서, 아키텍처에는 정답이 없고 주어진 환경과 목적에 맞는 최적의 타협점을 찾는 과정이 본질임을 깨달았습니다.