[허수아비] 프로젝트 회고
팀장 겸 인프라 담당으로 두 대의 EC2 제약 환경에서 전체 시스템을 설계·운영하며 겪은 WebRTC ICE 타임아웃, MinIO Mixed Content, Spark 리소스 쟁탈 등 실전 트러블슈팅 기록입니다.
 실시간 조회 페이지
실시간 조회 페이지
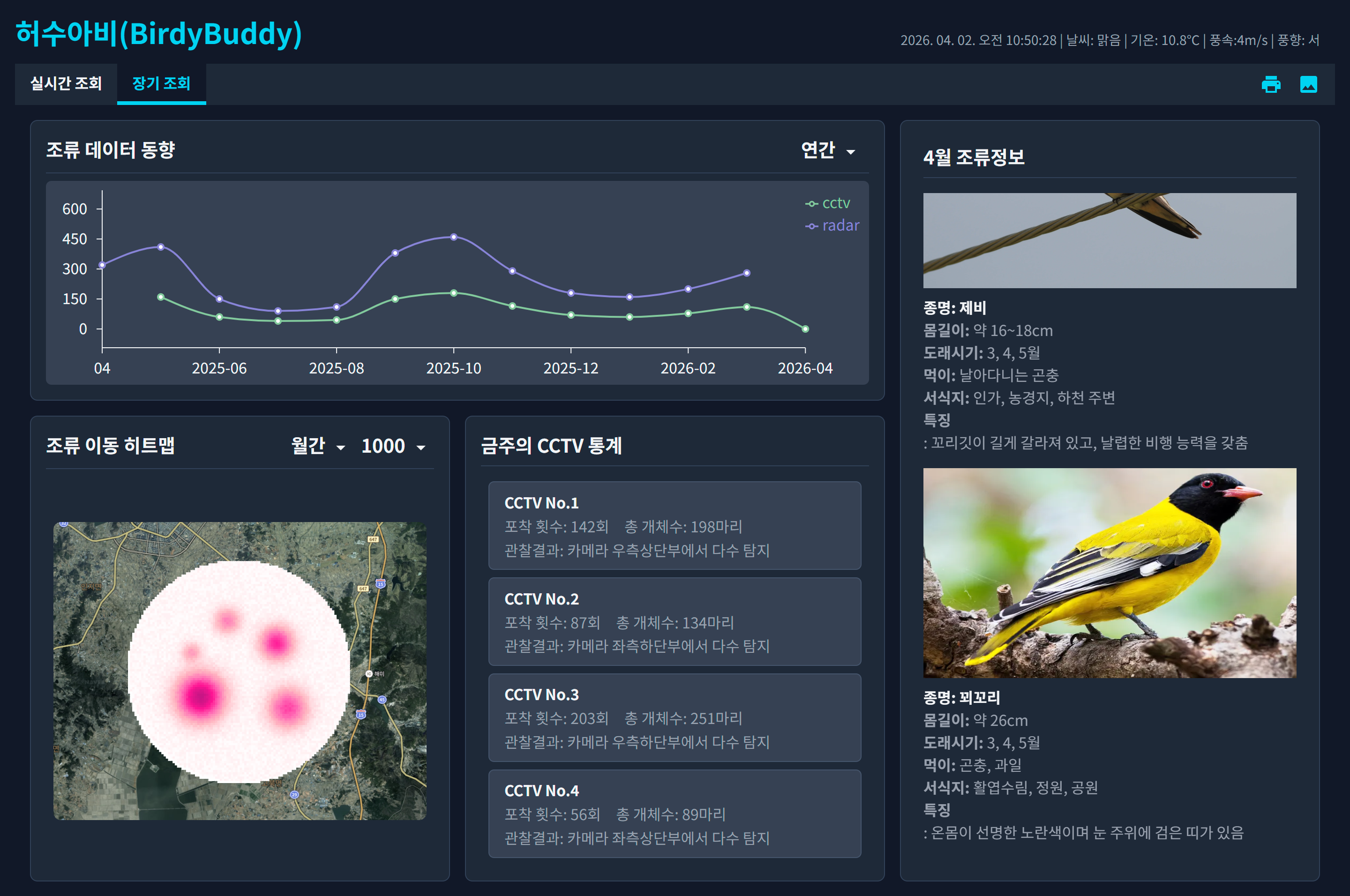 장기 분석 페이지
장기 분석 페이지
주요 담당 내용
팀장 겸 인프라/아키텍처 담당으로, 두 대의 EC2 제약 환경에서 전체 시스템을 배치하고 연결하는 역할을 맡았다.
| 담당 | 내용 |
|---|---|
| 멀티 EC2 배치 전략 수립 및 컨테이너 네트워크 설계 | 서비스별로 EC2 내부 docker network 통신과 외부 포트 기반 통신을 분리하고, 환경변수로 엔드포인트를 주입하는 구조를 정립했다. |
| WebRTC(HLS 포함) 스트리밍 제공 구조 설계 및 장애 대응 | ICE 연결 실패 시 HLS로 즉시 전환하는 경로를 설계하고, 근본 원인(보안 그룹 ICE 포트 차단)을 특정했다. |
| MinIO presigned URL / Mixed Content / Reverse Proxy 문제 해결 | 내부 주소 노출과 서명 불일치 문제를 nginx 프록시 + MINIO_SERVER_URL 설정으로 해결했다. |
| CI/CD 및 환경변수 관리 정책 정리 | 배포 재현성과 안정성 향상을 위해 환경변수 구조와 배포 흐름을 문서화했다. |
트러블슈팅
1. WebRTC ICE 타임아웃 → HLS 대체 경로 확보
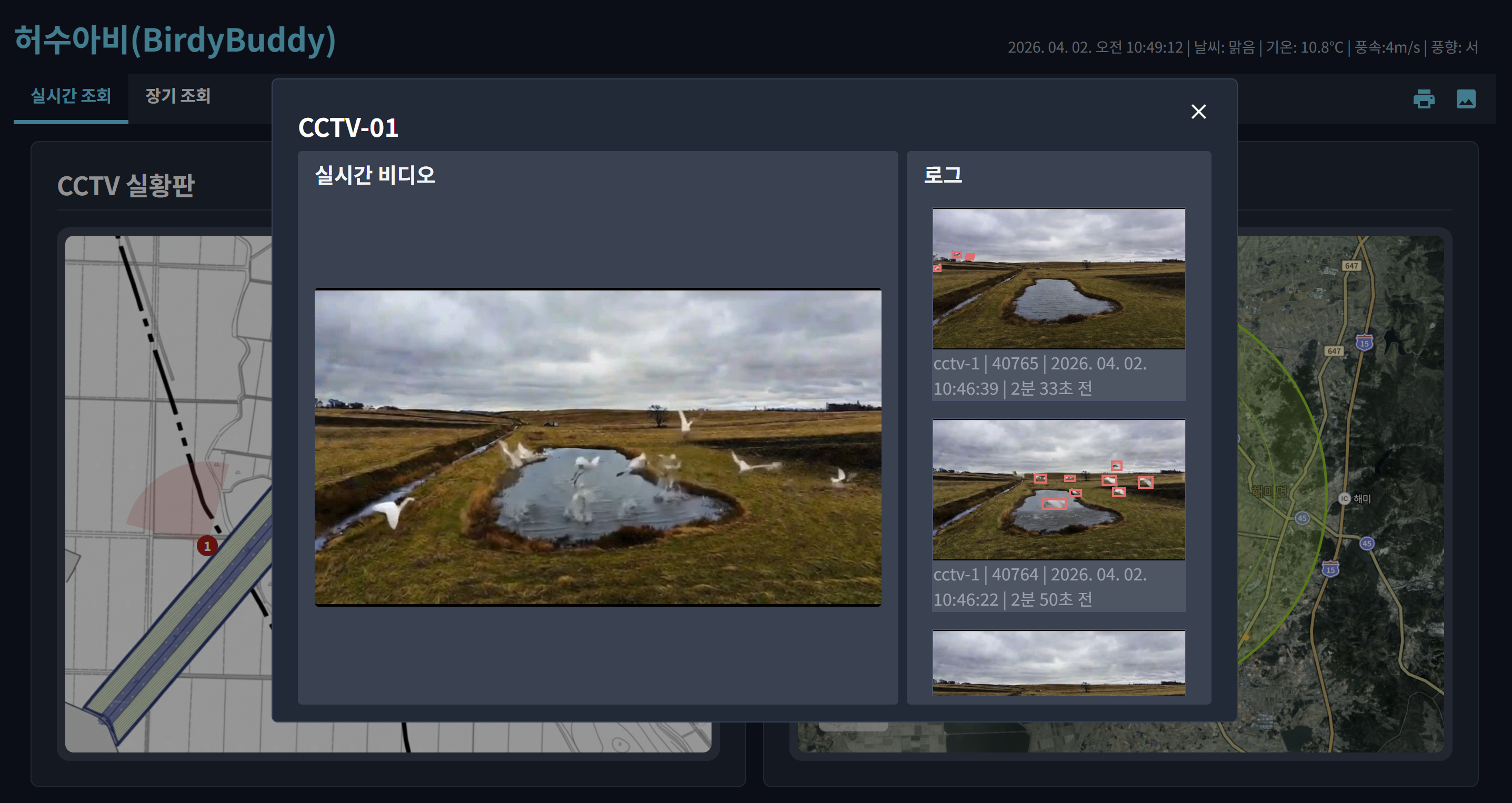 HLS로 구현한 CCTV streaming
HLS로 구현한 CCTV streaming
- 문제: WHEP 시그널링은 성공했지만, ICE 연결 단계에서 타임아웃이 나며 영상 재생 불가
- 원인:
ufw는 열려 있어도 AWS 보안 그룹이 ICE용 UDP/TCP 포트를 차단 (인프라 권한 제약으로 직접 수정 불가) - 해결:
- WebRTC 연결 흐름을 시그널링 / ICE(미디어) 단계로 분리해 원인 구간을 특정
- HLS는 HTTP 기반이라 기존 포트(8888/8889)로 제공 가능 → nginx 프록시로
.m3u8경로를 MediaMTX에 전달하고, 프론트는 hls.js로 재생 - 시연 리스크를 즉시 제거하고, “보안 그룹 ICE 포트 개방 요청”이라는 명확한 액션 아이템으로 정리
- 배운 점: “동작한다/안 한다”가 아니라 프로토콜 단계별로 분해하면 원인 규명이 빠르다. 제약이 있는 환경에서는 완벽한 해결보다 시연 리스크 제거가 먼저다.
2. MinIO 이미지 로드 실패 (s3:// 스킴 노출, Mixed Content, 서명 불일치)
- 문제: 이벤트 로그 화면에서 이미지가 로드되지 않음.
s3://스킴 노출,http://minio:9000presigned URL로 인해 Mixed Content 차단, 외부 브라우저에서 docker 내부 hostname 접근 불가 - 원인: presigned URL이 내부 hostname 기준으로 생성되어, 외부에서 접근도 불가하고 서명 검증 시 Host 불일치 발생
- 해결:
- nginx에 MinIO 프록시(
/birdybuddy/) 추가 +proxy_set_header Host유지 - MinIO에
MINIO_SERVER_URL을 reverse proxy 주소로 설정해 서명 검증 기준을 맞춤 - 백엔드에서 내부 endpoint로 presigned URL 생성 후, public endpoint로 host만 교체
- nginx에 MinIO 프록시(
- 배운 점: 스토리지 이슈는 단순 URL 문제가 아니라 서명/Host 헤더/프록시 체인까지 연결된 시스템 문제다. 백엔드-프록시-스토리지를 한 덩어리로 보고 일관성 있게 맞춰야 한다.
3. 멀티 EC2 환경에서 컨테이너 간 네트워크 장애
- 문제: EC2가 분리된 상태에서 다른 EC2의 docker 내부 hostname(
media-proxy,kafka등)으로 접근을 시도하며 연결 실패 - 원인: 단일 호스트에서만 유효한 주소 체계를 멀티 호스트로 그대로 확장
- 해결:
- 같은 EC2 내부 → docker network 통신 / 다른 EC2·외부 → public IP + 외부 포트 통신으로 규칙을 명확히 분리
- 포트 맵 정리 후, 환경변수로 외부 endpoint를 주입하는 구조로 전환
- 배운 점: 컨테이너 네트워크는 단일 호스트에서는 투명하지만, 멀티 호스트에서는 네트워크 경계가 가장 큰 리스크다.
4. HLS 세그먼트 요청이 nginx SPA fallback에 가로채임
- 문제: HLS 재생 시
.m3u8·세그먼트 요청이 MediaMTX가 아닌 SPA fallback(index.html)으로 처리됨 - 원인: SPA
try_files설정이 스트리밍 경로보다 먼저 매칭 - 해결:
.m3u8·세그먼트 경로에 대한location블록을 앞에 배치해 우선 매칭되도록 nginx 규칙을 재정렬 - 배운 점: 프록시·라우팅 문제는 로그만 보면 애매하지만, 요청 경로가 어떤
location에 매칭되는지를 기준으로 보면 빠르게 해결된다.
5. Spark 잡이 리소스를 못 받아 멈춤 → 코어 상한 + 메모리 분할로 안정화
- 문제:
spark-radar-stream로그에서 15초 간격으로Initial job has not accepted any resources경고가 반복되며 스트림 처리가 중단됨. 결과적으로radar.transformed토픽에 메시지가 발행되지 않아 레이더 변환 파이프라인이 끊김 - 원인:
- (코어) 먼저 제출된 잡이 워커 코어를 전부 선점해 다른 잡이
cores=0으로 대기 - (메모리)
SPARK_EXECUTOR_MEMORY=2g설정으로 executor 1개가 워커 메모리(2GB) 전체를 점유
- (코어) 먼저 제출된 잡이 워커 코어를 전부 선점해 다른 잡이
- 해결:
- Spark Master UI/API에서 active app의 cores/memory 할당 상태를 확인해 병목을 정량적으로 분리
spark.cores.max로 잡당 코어 상한을 설정해 Greedy allocation 방지 (.env에SPARK_MAX_CORES=1→ spark session에 반영)- 워커 가용 메모리를 명시(
SPARK_WORKER_MEMORY=3g)하고, 각 서비스의 driver/executor 메모리를 512m~1g 단위로 분할해 동시 실행 가능하게 조정
- 배운 점: 분산 처리 장애는 “Spark가 이상함”이 아니라 리소스 스케줄링 정책이 암묵적(default)이라서 생기는 경우가 많다. 로그만 보지 말고 Master UI/API로 cores/memory를 수치로 확인하면 원인(코어 vs 메모리)을 빠르게 분리할 수 있다.
인사이트
인프라를 처음부터 끝까지 맡아본 건 이번이 처음이었다. 말 그대로 “아무것도 없는 상태”에서 시작해서, 팀이 개발을 굴릴 수 있는 기반을 깔고, 배포 환경을 만들어서, 서비스가 끝까지 돌아가게 만드는 역할이었다.
근데 시작부터 마음처럼 되지는 않았다. SSAFY 계정으로 진행하다 보니 권한이 어떻게 주어졌는지조차 확인할 방법이 없었고, AWS 콘솔 접근도 자유롭지 않아서 계속 추상적이고 답답한 느낌이 있었다. 이걸 확인하려면 콘솔을 봐야 하는데 못 보는 상황이 반복되니까, 머릿속으로만 구조를 그리면서 판단해야 했고 그게 생각보다 꽤 부담이었다.
초반: 이해보다 속도
초반에는 서비스 구현에 필요한 기술 스택을 내가 다 파악하지도 못한 상태였다. Kafka, Spark, Hadoop, AI 워커, 백엔드, 프론트까지… 뭘 어떻게 엮어서 어떤 흐름으로 돌아갈지 정리도 덜 된 상태에서 아키텍처를 설계하고, EC2에 컨테이너 환경을 구성해야 했다. 팀원들이 개발을 시작하려면 내 쪽이 빨리 열려야 했기 때문에, ‘이해하고 납득하면서 설계’하고 싶어도 시간이 허락을 안 했다. 결국 속도를 우선으로 두고 어떻게든 형태를 잡아나갔는데, 그 과정에서 내가 놓친 것들도 많았다.
중반: 로컬과 배포 사이
어찌저찌 설계를 끝내고 환경을 구성했지만, 다음 문제는 ‘로컬 개발 환경’과 ‘EC2 배포 환경’이 머릿속에서 계속 섞인다는 거였다. 팀원들은 당장 로컬에서 돌아가는 게 중요하고, 나는 배포된 후 운영 환경이 중요하니까 우선순위가 충돌했다. 나는 “급한 건 배포 환경이다”라고 생각해서 배포 쪽에 집중했고 그 결과 로컬 쪽은 충분히 챙기지 못했다. 후반에는 각자 로컬 테스트가 제대로 안 되는 지경까지 갔다고 하는데, 나는 로컬 테스트를 할 일이 거의 없어서 그걸 뒤늦게 알았다. 지금 생각하면 그때 더 일찍 균형을 잡았어야 했다.
후반: 머지 지옥과 git 수습
그래도 중반 이후에는 각자 개발이 진행되면서 ‘이제 좀 안정됐다’는 느낌이 들었다. 문제는 그게 착각이었다는 거다. 각 파트의 세부 프로젝트 구조는 내가 직접 관여하지 않은 영역이 많아서 이해가 부족한 상태였고, 특히 백엔드 쪽은 바이브 코딩 느낌으로 빠르게 진행되다 보니 작업 상황이 서로 공유되지 않았다. 그러다 보니 개발 후반부에 머지하는 과정에서 서로 코드가 날아가고, 버전이 꼬이고, 컨테이너가 늘어나고, 정신이 정말 없었다. 그냥 엉망이었다.
git에 대한 이해가 부족한 상태에서 revert를 시도한 게 상황을 더 악화시키기도 했다. 일단 담당자가 해결해주길 기다렸는데 상황이 계속 악화되면서 후속 작업들이 줄줄이 블로킹됐다. 결국 내가 나서서 cherry-pick으로 필요한 커밋만 뽑아내는 방식으로 수습했다. 그때 느낀 건 “인프라만 잘한다고 끝이 아니구나”였다. 배포 환경은 결국 코드와 브랜치, 머지 전략 위에서 굴러가니까, git 흐름 자체를 안정시키는 것도 인프라에 가까운 일이라는 걸 체감했다.
그 이후에도 로컬에서 원격 최신 상태랑 싱크를 맞추는 방법이 잘못됐는지, 이미 머지된 다른 팀원의 커밋이 섞여서 PR이 올라오는 이슈가 있었다. 이런 건 겉으로는 사소해 보여도 막판에는 정말 치명적이다. “왜 여기서 이 커밋이 나와?” 같은 순간이 계속 나오면 신뢰가 무너지고 속도가 급격히 떨어진다.
마무리: 수습의 연속
배포 트러블은 끊이지 않았다. 로컬에서는 잘 돌아가는데 배포 환경에서는 안 돌아가는 경우가 생각보다 많았다. 이럴 때는 결국 데이터 흐름을 따라 하나씩 체크할 수밖에 없었다. 로그를 찍어보고, 컨테이너 간 통신을 확인하고, 포트 설정을 바꿔보고, 환경 변수를 다시 정리하고, 네트워크 구성을 다시 보고… 그렇게 한 단계씩 좁혀가는 방식으로 해결했다.
이 과정을 전부 내가 완벽히 이해하고 해결하기에는 시간이 너무 촉박했다. AI 도움을 많이 받을 수밖에 없었고, 당장 해결은 했지만 깊게 파고들지 못한 채로 지나간 부분이 많아 아쉬움이 남는다.
그래도 결과적으로는 기획했던 내용을 끝까지 다 구현해냈다. 중간에 막히고 꼬이고 계속 수습하면서도 결국 서비스가 돌아가게 만들었다는 건 확실히 잘한 점이라고 생각한다.
느낀 점
이번 프로젝트에서 느낀 점은 꽤 명확하다.
첫째, 인프라는 “처음부터 완벽하게” 만들 수 있는 게 아니라, 결국 팀의 개발 흐름에 맞춰 계속 조정되는 살아있는 구조라는 거다. 초반에는 빨리 열어줘야 한다는 압박 때문에 속도를 택했는데 그 선택이 후반에 빚으로 돌아온 것도 있었다.
둘째, 환경을 안정시키는 것만큼이나 커뮤니케이션과 규칙을 먼저 세우는 게 중요하다. 브랜치/커밋/MR 컨벤션 같은 기본 규칙을 더 강하게 잡고, 실제로 지켜지게 만들었다면 후반부 머지 지옥이 덜했을 것 같다. 프로젝트 페이지에 정리했던 브랜치, 커밋, MR 형식 같은 것들도 결국은 “문서화”에서 끝나면 의미가 없고, 팀이 실제로 굴러가게 해야 한다는 걸 배웠다. 이게 잘 적용되려면 팀원들의 협조가 필수적인데, 참여를 이끌어내지 못했다는 점에서 팀장으로서 역량이 부족했던 것 같다.
셋째, 로컬과 배포 환경을 동시에 챙기는 감각이 필요하다. 나는 배포 환경을 더 중요하게 봤는데, 팀 전체 생산성은 로컬 개발 경험에서 많이 갈린다. 배포만 빨리 만들어놓는다고 개발이 빨라지지 않는다는 걸 후반에 크게 느꼈다.
마지막으로, 이번 프로젝트는 나한테 ‘처음’이 너무 많았다. 처음 맡는 인프라, 팀장으로서의 책임감, 제한된 권한, 빠듯한 일정, 복잡한 스택, 그리고 막판의 혼돈까지. 중간중간 진짜 답답하고 힘들었지만 그만큼 실제로 운영 환경에서 무엇이 문제를 만드는지, 어떤 방식으로 좁혀가야 하는지 감이 생겼다.
아쉬움도 분명히 남는다. 촉박한 일정 때문에 이해를 덜 한 채로 넘어간 부분들이 많고 AI 도움으로 해결한 문제들을 내 것으로 완전히 흡수하지 못했다. 다음에는 ‘일단 되게 만들기’에서 끝내지 않고, 왜 그렇게 되는지까지 정리해서 남기는 걸 목표로 하고 싶다.
그래도 이번 한 번으로 얻은 경험치는 꽤 크다. 처음부터 끝까지 책임지고 굴려보면서, 인프라가 단순히 배포만 하는 게 아니라 팀의 개발 속도와 안정성을 좌우하는 기반이라는 걸 제대로 배웠다.