[둥지] 운영 알림 설계: Discord 웹훅으로 워커 사망·잔액 부족 감지하기
워커 사망, IROS 잔액 부족, OpenAI quota 초과 등 즉각 대응이 필요한 운영 이벤트를 Discord 웹훅으로 알림 받도록 구현한 과정을 기록합니다. 알림 채널 선택, 공통 모듈 설계, 트리거 포인트 결정 근거를 중심으로 정리합니다.
운영 중 워커가 죽거나 IROS 선불 잔액이 소진되면 사용자 요청이 전부 실패하는 상황이 됩니다. 그런데 감지 수단이 없었습니다. 사용자 민원이 들어오거나 Celery Beat가 찍는 WORKER_DEAD 로그를 직접 확인하기 전까지는 아무도 모르는 구조였습니다. 개발자가 인지할 수 있는 알림 채널이 필요했습니다.
알림 채널: Discord
Slack, PagerDuty, Sentry, 이메일 등을 검토했습니다.
| 옵션 | 탈락 이유 |
|---|---|
| Slack Incoming Webhook | 팀이 Slack을 메인으로 쓰지 않음. 무료 플랜 메시지 90일 보존 제한 |
| PagerDuty / OpsGenie | 온콜 로테이션·에스컬레이션 정책은 현재 팀 규모에서 오버스펙. 유료 |
| Sentry | 에러 집계 목적이지 운영 알림 특화 아님. 별도 도입 비용 |
| 이메일 (SES/SendGrid) | 실시간성 부족 |
Discord를 선택한 이유는 세 가지입니다.
- 팀이 실제로 사용 중이라 별도 채널 개설만으로 즉시 수신 가능합니다.
- Webhook URL 발급만으로 동작해 서드파티 계정·플랜이 필요 없습니다.
- embed 형식으로 색상·필드 구조화가 가능해 가독성도 확보됩니다.
공통 모듈 설계
모듈 위치
백엔드와 각 워커(clause/issuance/ocr)는 독립 Docker 컨테이너로 운영됩니다. 코드 공유가 불가능하므로 동일한 alerting.py 파일을 각 서비스에 복사하는 방식을 택했습니다.
1
2
3
4
doongzi-backend/app/core/alerting.py
doongzi-doc-worker/clause-worker/worker/alerting.py
doongzi-doc-worker/issuance-worker/worker/alerting.py
doongzi-doc-worker/ocr-worker/worker/alerting.py
인터페이스
1
2
3
4
5
6
def send_discord_alert(
title: str,
description: str,
level: Literal["critical", "warning", "info"] = "critical",
fields: dict[str, str] | None = None,
) -> None: ...
동작 규칙
| 규칙 | 근거 |
|---|---|
| 동기 함수 | Celery worker는 동기 컨텍스트 — async 함수 호출 시 이벤트 루프 충돌 위험 |
| URL 미설정 시 로그만 출력 | 로컬 개발 환경에서 URL 없이도 동작해야 함 |
| Discord 발송 실패 시 예외 raise 안 함 | 알림 실패가 태스크 자체를 망가뜨리면 안 됨 |
| 색상 구분 (CRITICAL/WARNING/INFO) | 채널에서 심각도를 시각적으로 즉시 파악 |
User-Agent: DiscordBot (doongzi, 1.0) 명시 | Python urllib의 기본 User-Agent를 Discord가 403으로 차단. curl·PowerShell로는 정상 동작하지만 Python urllib 단독 호출 시 재현됨. DiscordBot 형식으로 명시하면 정상 수신 |
트리거 포인트
서비스를 운영하면서 개발자의 개입이 필요한 상황들을 4가지 뽑아서 웹훅 알림 트리거로 설정했습니다.
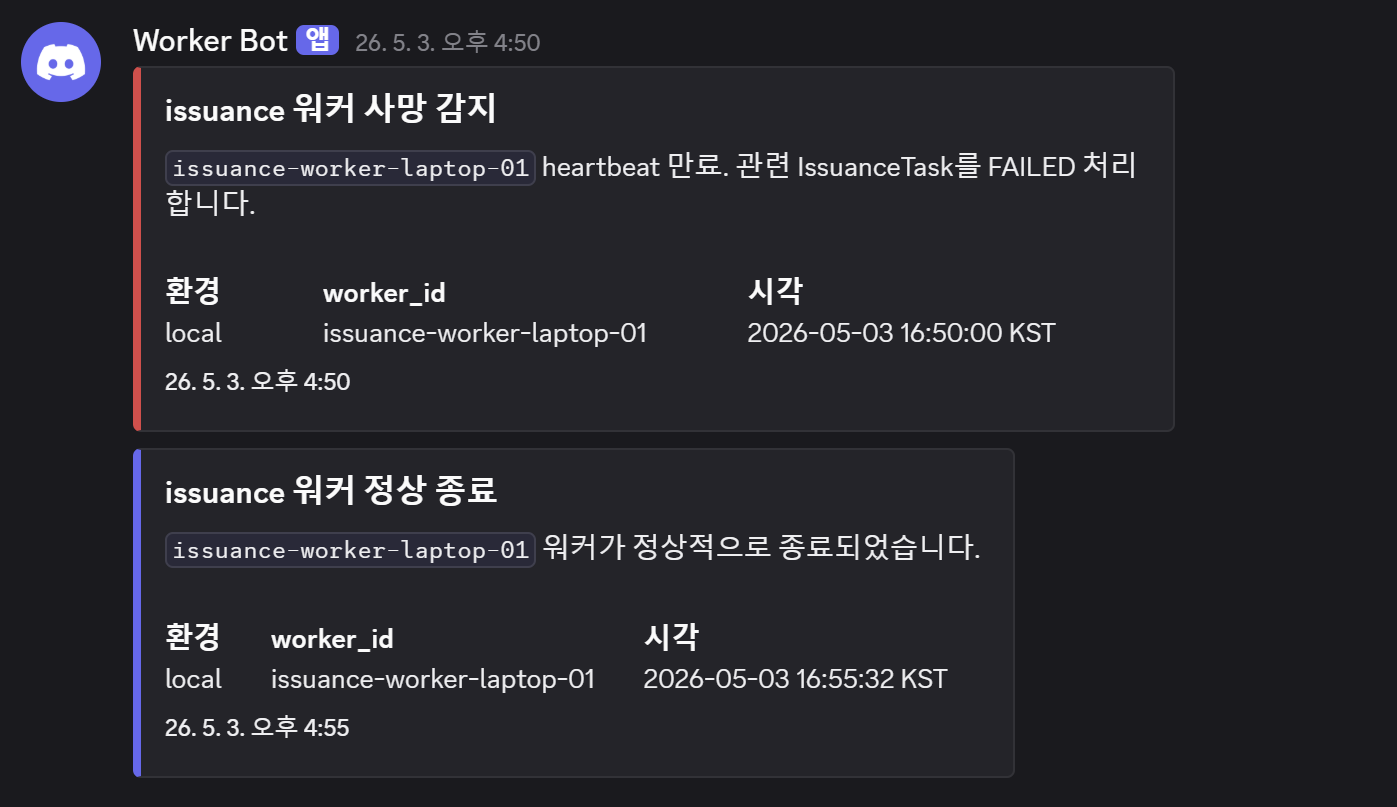
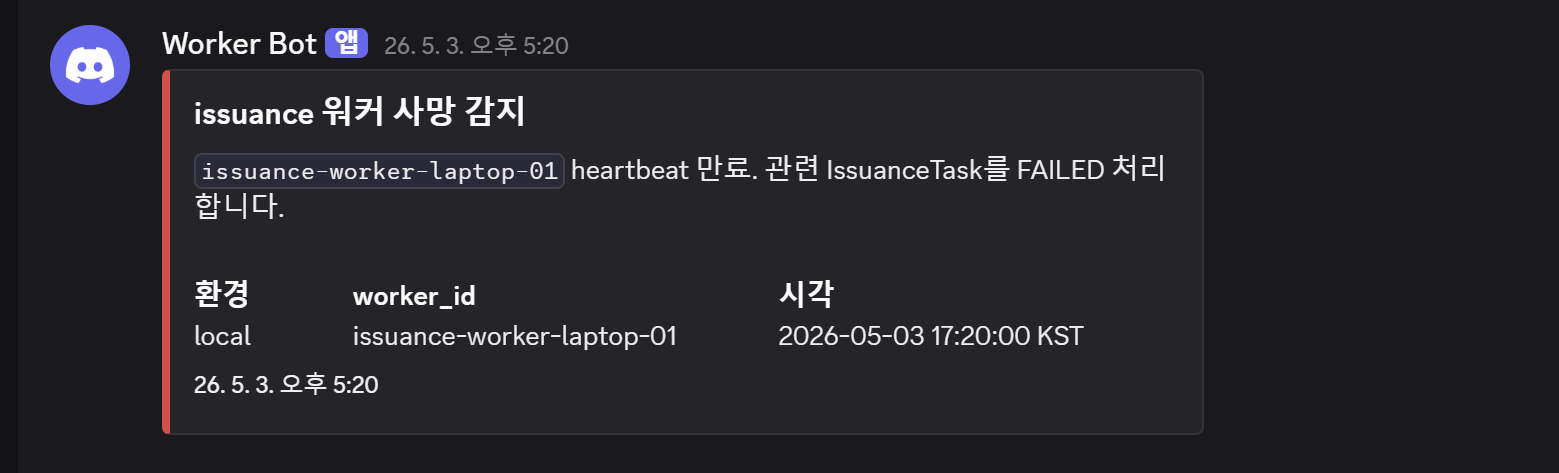
1. 워커 사망 감지
Celery Beat의 cleanup_stale_tasks가 heartbeat key 만료를 감지하고 WORKER_DEAD를 판정하는 시점이 유일한 단일 진입점입니다. 이 위치에 알림을 추가하면 별도 모니터링 로직 없이 완성됩니다.
worker_shutdown 시그널을 쓰지 않은 이유는, 정상 배포 시에도 발화하기 때문입니다. Beat에서 heartbeat 만료로 감지하는 것이 비정상 종료에 한정된 신뢰도 높은 신호입니다.
- 트리거 위치:
_cleanup_stale_tasks_async()—WORKER_DEAD판정 직후 - 노이즈 방지: 루프 종료 후 워커별 1회 알림 (모든 모델의 실패 건수 집계)
- 메시지 예시:
[CRITICAL] 워커 사망 감지 — issuance-worker-1 heartbeat 만료. (IssuanceTask 2건 영향)
2. IROS 선불 잔액 부족
현재 잔액 부족 시 Selenium bot이 팝업을 처리 못하고 AUTOMATION_FAILED로 떨어집니다. 자동화 실패는 재시도로 해결 가능하지만 잔액 부족은 즉시 충전이 필요한 운영 이슈입니다. 대응 방법이 전혀 달라 별도 예외 클래스(InsufficientBalanceError)와 에러코드(IssuanceErrorCodeEnum.INSUFFICIENT_BALANCE)를 추가했습니다.
- 트리거 위치:
_issue_registry_task_async()—InsufficientBalanceErrorcatch 블록 - 메시지 예시:
[CRITICAL] IROS 선불 잔액 부족 — 즉시 충전 필요 (issuance_task_id=...)
3. OpenAI API quota 초과
config.py에 OPENAI_API_KEY와 LLM_MODEL이 존재합니다. API quota 초과는 사용자 요청 전체가 실패하는 서비스 중단 수준의 이벤트입니다. openai.RateLimitError 또는 HTTP 429/402 응답 시 알림을 발송합니다.
- 메시지 예시:
[CRITICAL] OpenAI API quota 초과 — 크레딧 확인 필요
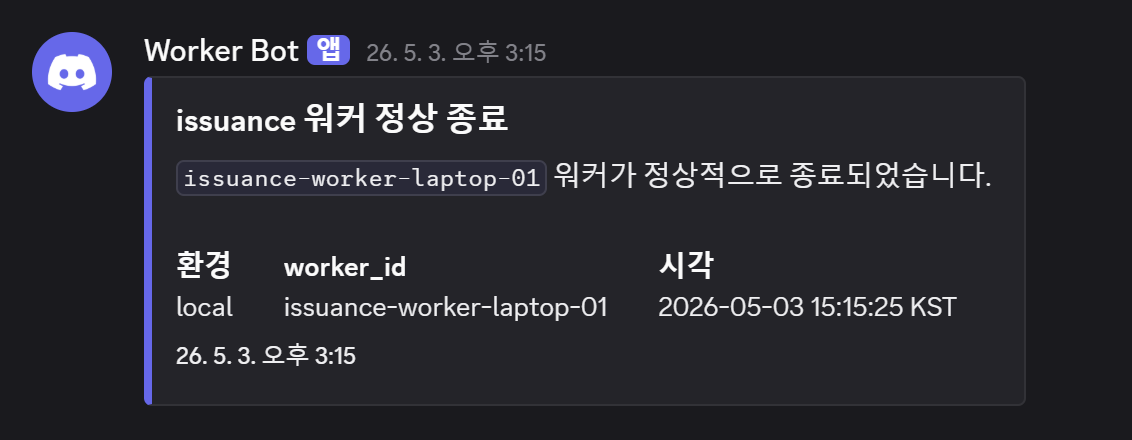
4. 워커 정상 종료
초기에는 ENV_MODE == "prod" 조건부로 프로덕션 한정 발송을 계획했습니다. 그런데 ENV_MODE는 어떤 .env.* 파일을 로드할지 결정하는 OS 레벨 환경변수라 .env.* 내부에 정의되지 않는 구조입니다. os.environ.get("ENV_MODE")로 읽을 수는 있지만, 프로덕션 컨테이너에 해당 변수가 실제로 주입된다는 것을 코드 레벨에서 검증할 수 없어 신뢰도가 낮았습니다.
대신 DISCORD_ALERT_WEBHOOK_URL 유무만으로 게이팅하기로 했습니다. .env.local에 URL을 넣지 않으면 로컬에서는 알림이 발송되지 않습니다.
- 트리거 위치: 각 워커
celery_app.py의on_worker_shutdown - 메시지 예시:
[INFO] clause-worker-1 워커 정상 종료
로컬 테스트: WORKER_DEAD는 Ctrl+C로 재현되지 않는다
Ctrl+C는 SIGTERM을 보내고 Celery graceful shutdown 경로를 탑니다.
1
2
3
4
5
6
7
SIGTERM 수신
→ Celery: 현재 task 완료 대기
→ Selenium bot이 interrupt 받아 exception raise
→ except Exception 블록 → AUTOMATION_FAILED 처리
→ task.status = FAILED (PROCESSING이 아님)
→ worker_shutdown 시그널 발화 → 정상 종료 알림 발송
→ beat 실행 시 PROCESSING 태스크 없음 → WORKER_DEAD 발생 안 함
task가 AUTOMATION_FAILED로 먼저 처리돼 Beat가 WORKER_DEAD를 판정할 PROCESSING 태스크가 없어집니다. 이 동작은 코드 버그가 아니라 SIGTERM의 예상된 결과입니다.
WORKER_DEAD를 올바르게 재현하려면 SIGKILL(강제 종료)을 써야 Python signal handler가 실행되지 않습니다.
1
2
3
4
5
# 워커 PID 확인
Get-Process | Where-Object { $_.Name -match "python" }
# 강제 종료
taskkill /F /PID <PID>
강제 종료 후 예상 흐름은 다음과 같습니다. on_worker_shutdown이 발화하지 않아 정상 종료 알림이 없고, task는 PROCESSING 상태로 DB에 남습니다. heartbeat Redis key TTL(90초) 만료 후 Beat가 다음 5분 crontab 실행 시 WORKER_DEAD를 판정하고 알림을 발송합니다. taskkill 직후부터 최대 6.5분(heartbeat TTL 90s + beat 최대 대기 5분)을 기다려야 알림이 옵니다.