[둥지] OCR 인프라 결정기: Lambda에서 Tailscale 셀프 호스팅 워커로
등기부등본 OCR을 AWS Lambda에 올리려다 OOM과 타임아웃 한계에 부딪히고, 결국 Tailscale VPN으로 로컬 디바이스를 Celery Worker로 연결하는 하이브리드 아키텍처로 전환한 과정을 정리합니다.
둥지 서비스에는 사용자가 업로드한 등기부등본 PDF를 OCR로 파싱하는 기능이 있습니다. 문제는 OCR 모델이 만만치 않다는 것이었습니다. 직접 학습한 게 아니라 오픈소스 모델(Surya)을 활용했는데, 가중치만 로드하는 데 수 GB가 필요합니다. 이걸 어디서 어떻게 실행할 것인가가 이번 아키텍처 결정의 핵심이었습니다.
처음엔 Lambda가 답처럼 보였다
OCR 요청이 얼마나 자주 들어올까요? 서비스 흐름상 사용자가 체크리스트를 시작할 때, 중간에 수정할 때 정도입니다. 많아야 서비스당 두세 번, 트래픽이 일정하지 않고 간헐적입니다.
이런 특성에 EC2는 낭비입니다. 트래픽이 없는 시간에도 인스턴스는 계속 돌아가고 비용이 청구됩니다. 반면 Lambda는 요청이 들어올 때만 실행되고, API Gateway와 바로 연동되며, 스케일링도 자동입니다. 배포 방식도 간단합니다.
1
2
3
4
5
6
7
Dockerfile
↓
docker build → ECR push
↓
Lambda 함수 (Image 방식으로 생성)
↓
API Gateway 연결
로컬에서 만든 OCR 파이프라인을 컨테이너 이미지로 패키징하고 ECR에 올린 뒤, Lambda가 그 이미지를 실행하는 구조입니다. 이론상으로는 깔끔한 그림이었습니다.
Lambda의 벽 — OOM
막상 배포해보니 모델 가중치를 로드하는 단계에서 바로 OOM(Out of Memory)이 발생했습니다. Surya OCR 모델의 가중치를 메모리에 올리는 데 약 3GB 이상이 필요한데, Lambda의 메모리 상한을 훌쩍 넘었습니다.
“그러면 모델 정밀도를 낮춰서 메모리를 줄이면 되지 않을까?”
FP32(float32) 가중치를 FP16(bfloat16)으로 변환하면 메모리가 절반 수준으로 줄어듭니다. 실제로 시도해봤더니 효과가 있었습니다.
| 설정 | 메모리 사용량 |
|---|---|
| FP32 (기본) | 약 4,505 MB |
| bfloat16으로 변환 | 약 509 MB |
메모리 문제는 해결됐습니다. 하지만 이번엔 다른 문제가 기다리고 있었습니다.
메모리는 줄었지만, 추론이 끝나지 않는다
 OOM
OOM
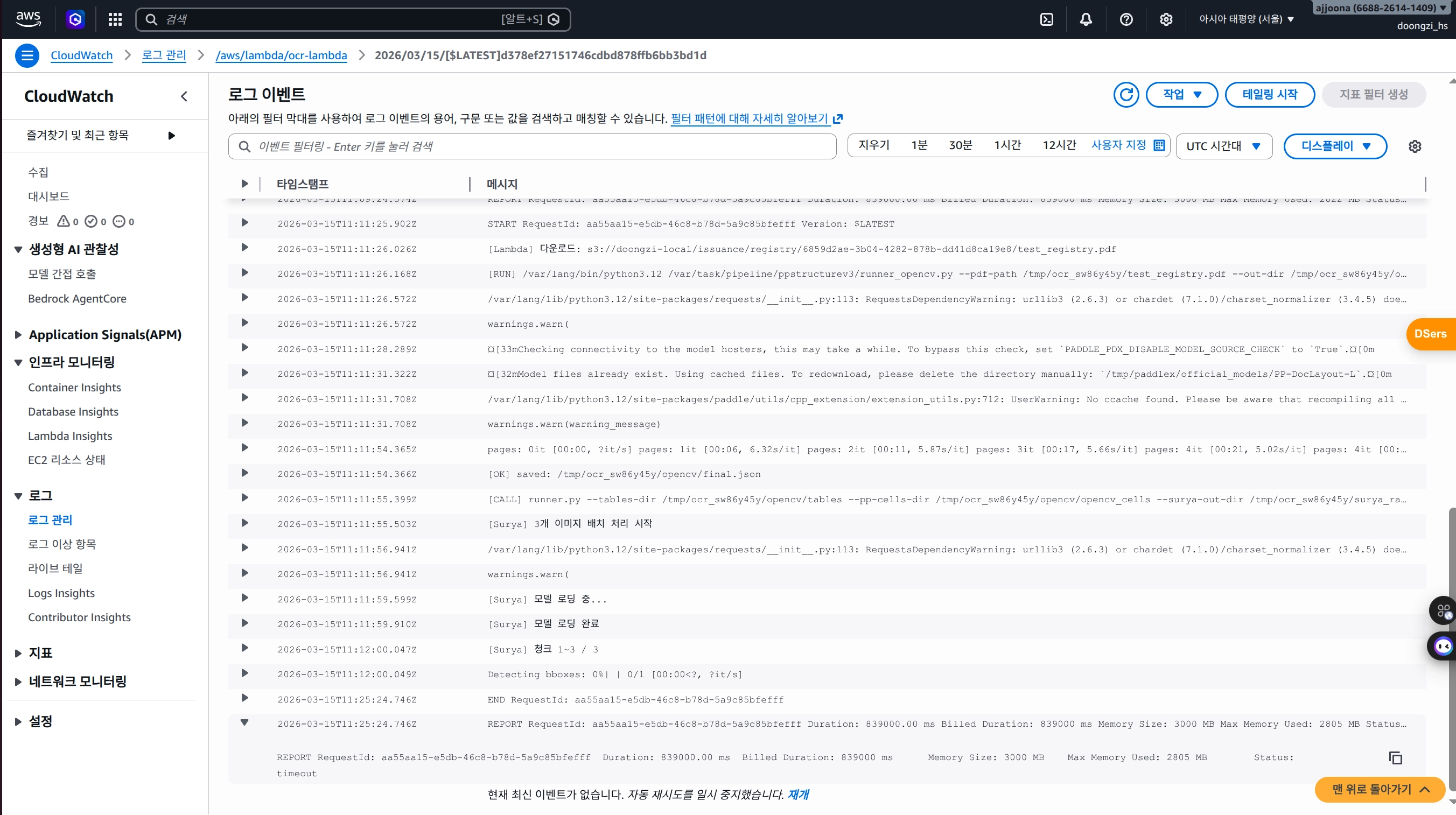
Lambda 메모리 적재에는 성공했지만 실제 OCR 추론이 14분이 지나도 완료되지 않았습니다. Lambda에는 최대 실행 시간 제한이 있고, 그 이상 걸리면 강제로 타임아웃됩니다.
원인은 CPU 기반 추론이었습니다. Lambda는 GPU를 지원하지 않고, OCR 모델은 이미지에서 텍스트를 검출하고 인식하는 과정에서 연산량이 상당합니다. 배치 크기를 줄이고 청크를 5로 제한해봤지만, CPU 환경에서는 근본적인 한계가 있었습니다.
Lambda는 이 용도에 적합하지 않다고 판단했습니다.
GPU 서버를 알아봤더니
Lambda를 포기하면 EC2로 돌아가야 합니다. 그런데 OCR에 GPU가 필요하다면 GPU 인스턴스를 써야 합니다. GPU를 붙이면 동일한 OCR 작업이 50초 내로 끝납니다.
문제는 비용입니다. AWS EC2 GPU 인스턴스는 월 10~20만 원 수준입니다. OCR 요청이 하루에 몇 건 안 되는 서비스에 매달 고정 비용을 내는 건 납득하기 어려웠습니다.
그때 아이디어가 하나 떠올랐습니다.
“GPU가 필요한 작업을 꼭 클라우드에서 할 필요가 있을까? 로컬 데스크탑이나 노트북을 워커로 쓰면 어떨까?”
셀프 호스팅 워커 — 로컬 디바이스를 Celery Worker로
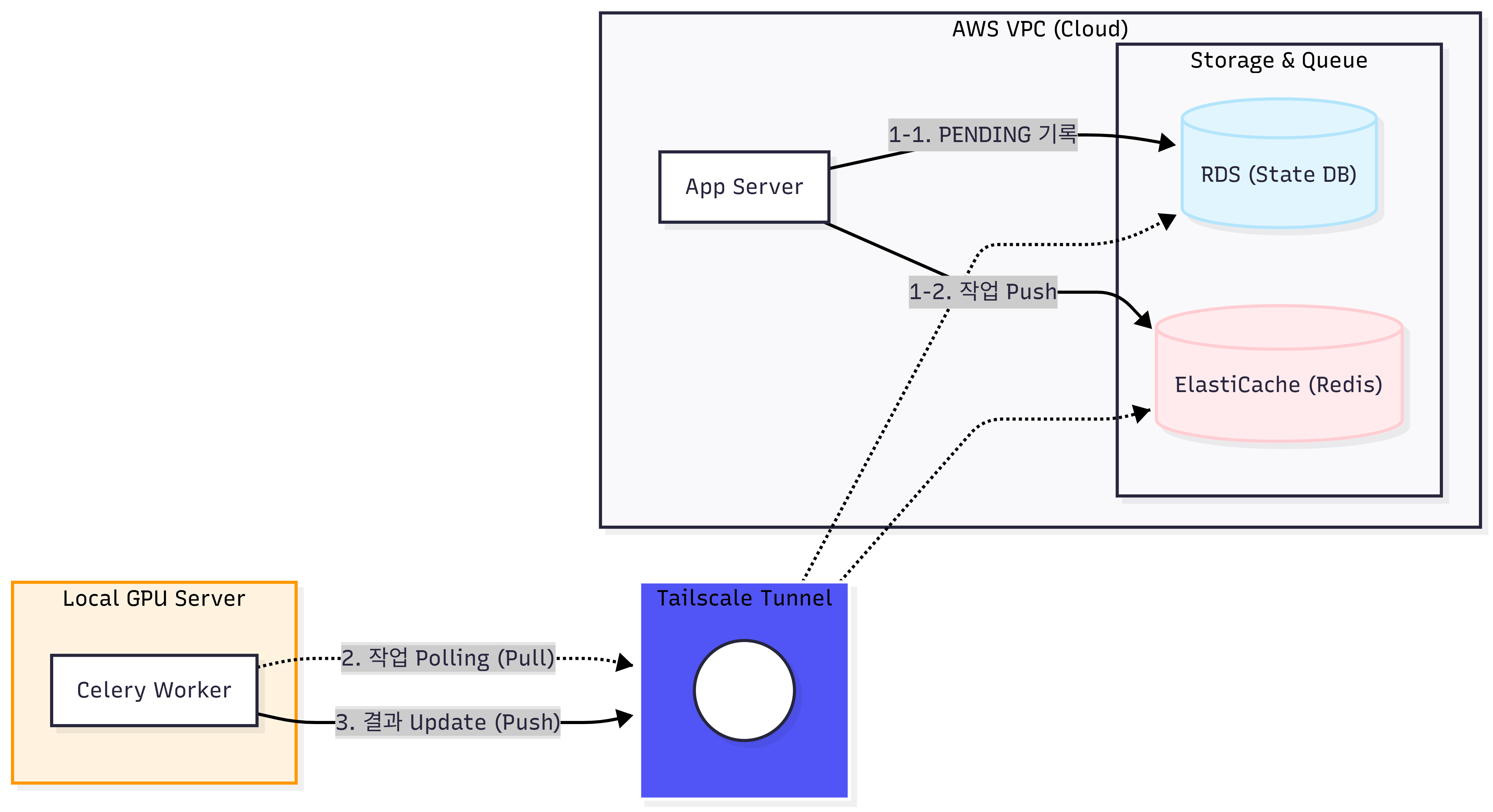
아이디어는 간단합니다. 메인 서버(EC2)는 OCR 작업 요청을 Redis 큐에 발행하기만 하고, 실제 추론은 GPU가 있는 로컬 디바이스에서 Celery Worker로 처리합니다.
이렇게 하면 GPU 비용이 제로입니다. 이미 가지고 있는 장비를 사용하는 것이니까요.
단, 한 가지 문제가 있었습니다.
ElastiCache는 외부에서 접근이 안 된다
둥지 프로젝트의 Redis는 AWS ElastiCache를 사용합니다. ElastiCache는 기본적으로 VPC 내부에서만 접근 가능하고, 외부 인터넷에서는 차단됩니다. 로컬 디바이스에서 EC2의 Redis에 직접 연결할 수 없다는 뜻입니다. RDS(PostgreSQL)도 마찬가지입니다.
이 문제를 Tailscale로 해결했습니다.
Tailscale로 EC2와 로컬을 하나의 가상망으로 연결
Tailscale은 기기 간 VPN을 구성해주는 서비스입니다. EC2와 로컬 디바이스 양쪽에 Tailscale을 설치하고 같은 계정으로 로그인하면, 두 기기가 하나의 프라이빗 가상망으로 묶입니다.
그리고 SSH 터널을 두 개 열어 로컬에서 ElastiCache Redis와 RDS에 접근할 수 있도록 했습니다.
1
2
3
로컬 워커 (Tailscale 연결)
├─ SSH 터널 → localhost:6379 → EC2 → ElastiCache Redis
└─ SSH 터널 → localhost:5432 → EC2 → RDS PostgreSQL
테스트한 아키텍처 흐름은 이렇습니다.
1
2
3
4
5
6
7
1. EC2 → ElastiCache Redis (OCR 작업 발행)
↓
2. 로컬 워커 → Redis polling (작업 꺼냄)
↓
3. 로컬 워커 → GPU로 OCR 처리
↓
4. 로컬 워커 → RDS (결과 INSERT)
테스트 결과 정상 동작을 확인했습니다. GPU를 활용하면 추론이 50초 이내로 완료됩니다.
운영 환경에서는 SSH 터널 대신 Tailscale 서브넷 라우팅 방식을 사용할 예정입니다. 서브넷 라우터를 EC2에 설치하면 Tailscale 네트워크에서 VPC 내부 리소스(ElastiCache, RDS)에 직접 접근할 수 있습니다.
비동기 태스크 분리 — send_task와 큐 라우팅
아키텍처가 정해졌으니 코드 레벨에서 어떻게 구현할지 설계했습니다.
아이디어는 OCR 워커의 코드를 메인 서버가 직접 임포트하지 않는 것입니다. 로컬 워커와 EC2 서버는 별도의 코드베이스로 동작하기 때문에 @shared_task로 정의된 함수를 직접 참조할 수 없습니다. 대신 Celery의 send_task를 사용해 이름 기반으로 태스크를 호출합니다.
1
2
3
4
5
# app/core/celery_app.py
# ocr 관련 태스크는 전용 큐로 라우팅
celery_app.conf.task_routes = {
"ocr.*": {"queue": "ocr"},
}
1
2
3
4
5
6
7
# app/domains/checklist/tasks.py
# 워커 코드를 임포트하지 않고 이름 기반으로 비동기 호출
celery_app.send_task(
"ocr.process_registry_document",
kwargs={"file_id": str(file_id), "s3_key": s3_key},
queue="ocr",
)
checklist 큐의 워커가 발급 태스크를 처리한 뒤 OCR 태스크를 Redis에 발행합니다. 이건 중첩 실행이 아니라 순차 체인입니다.
1
2
3
4
API 서버 → Redis (checklist 큐) ← issue_registry_task 발행
checklist 워커 → Redis (checklist 큐) ← 메시지 소비
checklist 워커 → Redis (ocr 큐) ← ocr 태스크 발행
ocr 워커 → Redis (ocr 큐) ← 메시지 소비
Redis 입장에서는 두 개의 독립된 큐 메시지일 뿐입니다. 중첩 실행 문제는 없습니다.
OCR 작업 상태를 어떻게 프론트에 전달할까
비동기 태스크는 결과를 즉시 반환하지 않습니다. 프론트에서 OCR이 완료됐는지 어떻게 알 수 있을까요?
Celery는 내부적으로 태스크 상태를 관리합니다.
1
2
PENDING → STARTED → SUCCESS
↘ RETRY (최대 2회, 30초 간격) → FAILURE
하지만 이 상태를 프론트가 직접 참조하게 만드는 건 좋지 않습니다. Celery 내부 구현에 프론트가 직접 의존하게 되면, 작업 처리 방식이 바뀔 때 프론트까지 영향을 받는 구조가 됩니다.
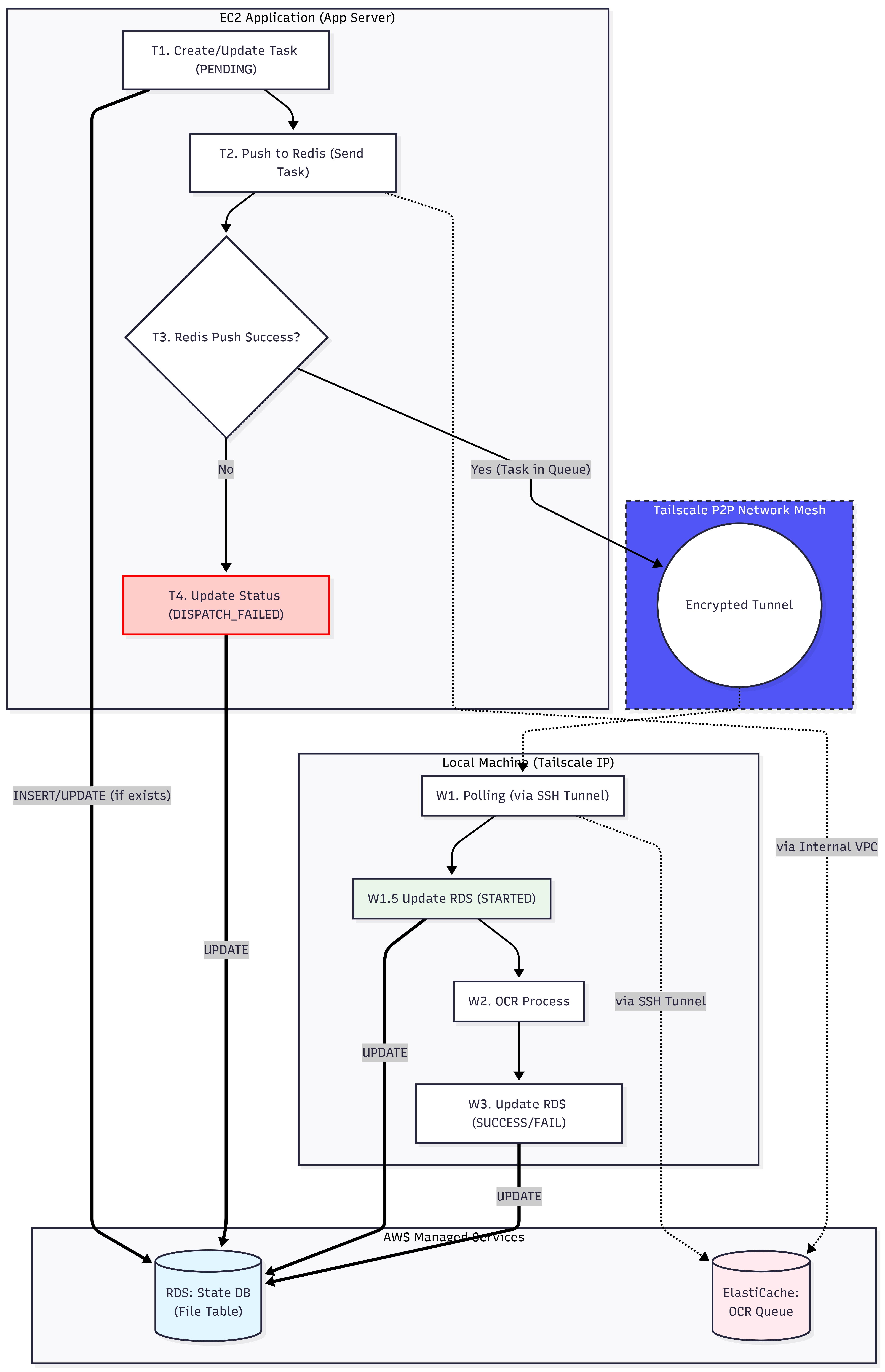
그래서 별도의 OcrTask 상태 관리 테이블을 DB에 두는 방식을 선택했습니다. 흐름은 이렇습니다.
 OCRTask 흐름도
OCRTask 흐름도
1
2
3
4
5
6
7
8
[API 서버]
작업 발행 → OcrTask 행 생성 (status: PENDING)
상태 조회 API → 3초 간격으로 폴링 응답
[OCR 워커]
작업 시작 → OcrTask 업데이트 (status: STARTED)
작업 완료 → OcrTask 업데이트 (status: SUCCESS)
작업 실패 → OcrTask 업데이트 (status: FAILURE)
프론트는 Celery를 모릅니다. 상태 조회 API만 polling하고, API는 항상 일관된 기준으로 상태를 제공합니다.
한 가지 엣지 케이스도 고려했습니다. Redis 작업 발행 자체가 실패하면 어떻게 될까요? 발행이 실패하면 OcrTask 행을 생성할 타이밍이 없어집니다.
해결 방법은 순서를 바꾸는 것입니다. OcrTask 행을 먼저 PENDING으로 생성한 뒤 Redis에 발행합니다. Redis 발행이 실패하면 이미 생성된 OcrTask 행을 DISPATCH_FAILED로 업데이트합니다. 동일한 file_id로 재시도가 들어오면 새 행을 만들지 않고 기존 행을 업데이트하는 방식으로 처리합니다.
최종 아키텍처 요약
 Tailscale과 셀프 호스팅 GPU 서버
Tailscale과 셀프 호스팅 GPU 서버
| 단계 | 선택지 | 결과 |
|---|---|---|
| Lambda | 이벤트 기반, 비용 효율적 | OOM, CPU 추론 타임아웃으로 포기 |
| EC2 GPU | 빠른 추론 (50초) | 월 10~20만 원 고정 비용 부담 |
| 셀프 호스팅 워커 | 로컬 GPU 활용 | Tailscale로 네트워크 연결, 제로 코스트 달성 |
Lambda 한계 → GPU 비용 문제 → Tailscale 하이브리드 워커로 이어지는 결정 과정이었습니다. 비용 제약 안에서 GPU를 활용할 수 있는 구조를 만들었고, 비동기 처리와 상태 관리도 프론트와의 결합도를 낮추는 방향으로 설계했습니다.