컬리의 개인화 추천 시스템 분석: Semantic ID와 Dual-Head 아키텍처
마켓컬리의 추천 시스템(Semantic ID, Dual-Head Architecture) 기술 블로그를 분석하고, 지식 증류와 데이터 엔지니어링 전략을 학습합니다.
상품과 유저를 표현하는 공간
 상품과 유저를 표현하기 위한 공간
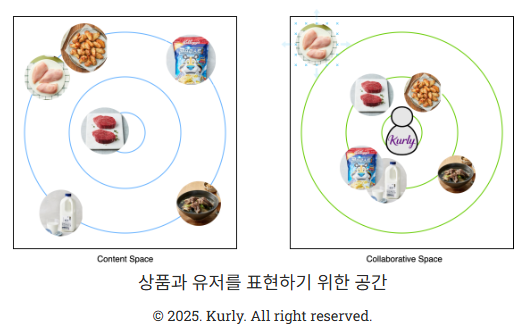
상품과 유저를 표현하기 위한 공간
- Content Space: 각 상품의 속성을 나타내는 공간
- 대체제 탐색 등 연관 상품 추천에 활용될 수 있다.
- 속성이 다른데 함께 구매하는 짝궁 상품(예: 우유와 시리얼)은 파악하기 어렵다.
- Collaborative Space: 유저의 취향과 행동 패턴이 반영된 공간
- 개인화 추천에 활용될 수 있다.
- 같이 구매하는 상품들이 가깝게 위치한다.
두 공간은 서로 독립적인 것이 아니고, 상품의 속성(Content)으로부터 정의한 언어로 유저의 행동(Collaborative)을 해석하는 방식으로 작동한다.
Semantic ID
상품의 언어를 정의하기 위해 각 속성을 ID로 표현, 여러 개의 속성을 나열한 새로운 Semantic ID를 만들어 표현했다.
예를 들어 컬리에서 판매 중인 [KF365] 무농약 국산콩 콩나물 300g 라는 상품은 이렇게 변환될 수 있다.
1
2
3
4
5
6
[상품 유형: 콩나물(채소류)] → Codebook A, index 27
[원산지: 국내산] → Codebook B, index 12
[생산 방식: 유기농] → Codebook C, index 3
[용량/규격: 300g] → Codebook D, index 8
Result: Semantic ID = [27, 12, 3, 8]
Dual-Head Architecture
유저의 취향을 저격하는 추천을 위해 두 가지 방법을 동시에 사용한다.
Generative Head (예측)
“다음에 무조건 살 것 같은 상품 딱 하나는?”
하나하나 따져보고 유저의 미묘한 맥락까지 파악해 정확도가 높으나, 그만큼 계산이 느려서 실시간 추천에 쓰기는 어렵다.
Retrieval Head (유사도 검색)
“주어진 상품 중 가장 살만한 상품은?”
Collaborative Space에서 단순 벡터 유사도 검색으로, 빠르게 후보 상품을 추려낼 수 있다. 대신 정확도가 떨어진다.
Knowledge Distillation
Retrieval Head가 빠른 반면에 성능이 떨어지고, Generative Head는 똑똑한 반면에 너무 느리다. 이 문제를 ‘표현력 병목(Representation Bottleneck)’으로 두고, Retrieval의 속도에 Generative의 넓은 시야(Distribution)를 이식하는 지식 증류(Knowledge Distillation) 전략을 도입했다. 똑똑한 Generative Head가 Retrieval Head에게 예측 점수를 전수해주어 정보의 공백을 메우는 방법이다.
이때, Generative Head의 출력은 각 코드별 logits이기 때문에 그대로는 확률로 해석할 수 없다. 그래서 각 시점의 logits을 softmax로 변환해 코드별 Log-Likelihood를 계산하고, 이를 합해 최종 아이템 생성 확률로 표현했다. 덕분에 Retrieval Head는 단순한 정답/오답 이분법이 아닌, 미래 구매 가능성까지 반영한 임베딩 공간을 학습할 수 있게 되었다.
데이터 엔지니어링
모델을 더 잘 가르치기 위해 몇 가지 작업을 더했다.
장바구니에 담은 시간 순서를 인식하는 대신, 주문 단위의 위치 정보(Order Positional Encoding)를 도입했다. 같은 주문서에 담긴 상품들에게 동일한 시점 정보를 부여함으로써, “시리얼과 우유를 같이 샀다(동시)”는 맥락을 구분하여 학습할 수 있다.
향상 잘 팔리는 품목들(예: 계란, 우유, 두부 등)만 추천하지 않도록, 인기 상품의 영향력을 낮췄다. 아이템 빈도수와 반비례하는 가중치를 적용함으로써 인기가 너무 많은 상품의 등장 확률을 적절히 눌러준다. 이로써 인기 편향 (Popularity Bias) 문제를 해결하고 유저의 취향을 저격할 비인기 상품도 골고루 학습할 수 있게 했다.
경우의 수가 수천억에 달하는 유저·상품 페어를 전부 학습할 수 없다. 같은 카테고리 내의 다른 상품이나 과거에 구매했던 상품을 의도적으로 오답(Negative)으로 섞어, 모델이 단순한 카테고리 구분을 넘어 미세한 속성 차이까지 학습하도록 하는 Hard Negative Mining 전략을 도입했다.
 컬리 앱의 추천 상품
컬리 앱의 추천 상품