당근 테크 블로그 분석: 저장 중심에서 활용 중심의 데이터 설계로
당근의 'User Activation 전사 공통 데이터 레이어' 구축 사례를 분석합니다. Fact 레이어와 3가지 모델(FirstLast, Activation, Status)을 통해 비용 효율성과 신뢰성을 모두 잡은 설계를 살펴보고, DB 설계에 대한 관점을 재정립합니다.
평소 개발을 하면서 데이터베이스를 설계할 때, 나의 주된 관심사는 데이터 정규화(Normalization) 혹은 모델을 어느 앱에 위치시킬지였다. 중복을 최소화하고, 이상 현상(Anomaly)을 방지하며, 효율적으로 저장하는 시스템적인 구조에만 집중했던 것이다.
하지만 최근 당근 테크 블로그의 [User Activation을 전사 공통 데이터 레이어로 만들며 해결한 3가지] 포스팅을 읽고, 데이터 설계에 대한 시야가 좁았음을 깨닫게 되었다.
Fact 레이어와 Activation의 3가지 모델
당근은 유저가 현재 어떤 상태(신규, 유지, 복귀, 이탈)인지와 상태 간의 이동(Flow)을 파악하기 위해 Activation 레이어를 구축했다.
기존에는 팀마다 제각각 쿼리를 짜서 데이터를 분석하다 보니 신뢰성과 생산성이 떨어졌는데, 이를 전사 공통 레이어로 추상화하여 해결했다는 내용이다. 특히 Base → Fact → Activation으로 이어지는 계층 구조 설계가 인상적이었다.
이 글에서 가장 인상 깊었던 점은 ‘어떻게 하면 신뢰할 수 있고 비용 효율적으로 사용할 수 있을까?’를 고민하여 계층을 나누고 모델을 구조화했다는 점이다.
1. 의미를 담은 ‘Fact 레이어’
보통 로그 테이블은 원천 데이터(Raw Data)를 그대로 쌓기 바쁘다. 하지만 당근은 이를 비즈니스 로직이 포함된 Fact 레이어로 한 번 정제하여 관리한다.
“Fact 레이어는 사용자 행동을 정의해두는 계층이에요. 단순한 행동부터 조건과 비즈니스 로직이 필요한 행동(예: ‘사용자가 액티브하게 피드를 사용했다’)까지, 의미가 담긴 행동 단위로 표현되도록 운영하고 있어요.”
이렇게 하면 분석가는 복잡한 WHERE 절을 매번 작성할 필요 없이, ‘정의된 행동’을 바로 가져다 쓸 수 있다.
2. 성능과 활용을 모두 잡은 ‘Activation 레이어의 3개 모델’
특히 Activation 레이어를 구성할 때, 하나의 통짜 테이블이 아니라 역할에 따라 3가지 모델이 한 세트로 동작하도록 설계한 부분이 인상적이었다.
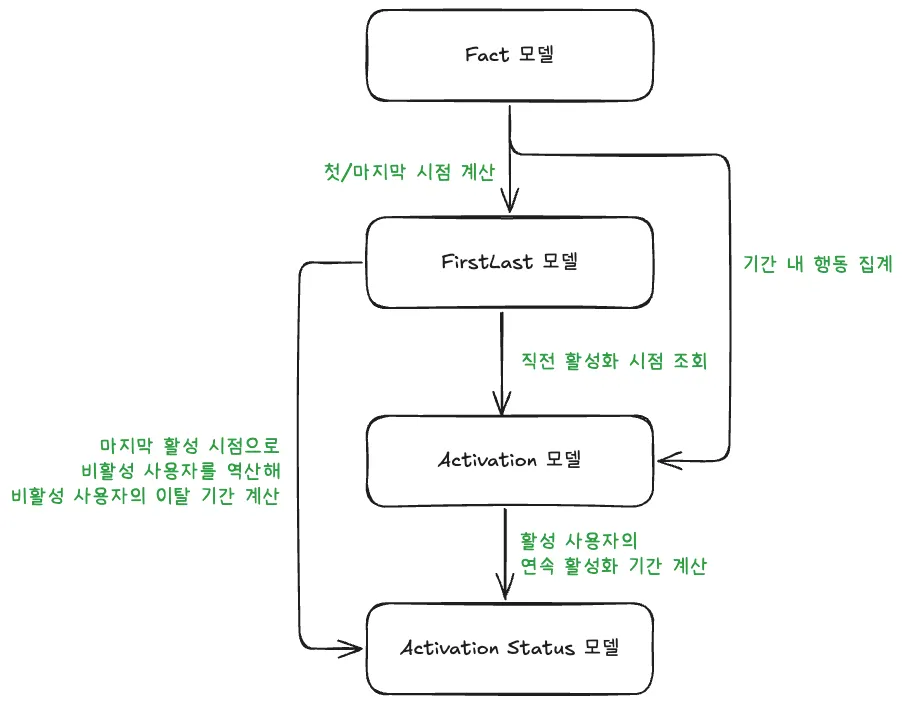 Activation 레이어 내 3개의 모델의 데이터 흐름도
Activation 레이어 내 3개의 모델의 데이터 흐름도
FirstLast 모델 (비용 최적화): 유저의 최초 활동일(First)과 마지막 활동일(Last)만 따로 관리하는 중간 테이블이다. 이를 통해 매번 전체 기간의 방대한 로그를 스캔하는 비용을 획기적으로 줄였다.
Activation 모델 (기준 명확화): Fact 모델을 입력으로 받아 실제 활성 여부를 계산한다. 모델명에 기준 행동(Fact)을 명시하여 누가 봐도 무엇을 측정한 것인지 알 수 있게 했다.
Activation Status 모델 (상태 정의): 최종적으로 유저의 상태(신규, 유지, 복귀, 이탈)와 상태 전이(Flow)를 보여준다.
단순히 “데이터가 있다”가 아니라, 비용을 아끼면서(FirstLast) 명확한 기준(Activation)으로 상태를 보여주는(Status) 유기적인 설계였다.
느낀 점: 저장하는 데이터 vs 활용하는 데이터
이 글을 읽으며 가장 크게 와닿았던 점은 실제 서비스를 운영하고 유저 데이터를 받아서 활용하는 것까지 멀리 내다봐야 한다는 것이다.
그동안 나는 DB 스키마를 짤 때 ‘어떻게 잘 저장할까(Storage)’만 고민했다. 하지만 서비스가 성장하고 데이터가 쌓이면, 결국 그 데이터를 꺼내서 ‘어떻게 유효하고 유용하게 사용할 것인가’가 비즈니스의 핵심이 된다. 분석하기 어렵게 파편화된 데이터는 죽은 데이터나 다름없기 때문이다.
당근이 도입한 FirstLast 모델만 봐도 그렇다. 개발 관점에서는 굳이 중간 테이블을 만들 필요 없이 쿼리로 조회하면 그만이라고 생각할 수 있다. 하지만 데이터의 규모가 커지고 매일 반복되는 연산 비용을 고려하면, 중간 테이블을 두는 것이 훨씬 효율적인 ‘설계’가 된다.
앞으로 프로젝트를 진행할 때는 단순히 정규화 원칙만 따질 것이 아니라, “이 데이터가 나중에 분석가나 기획자에게 어떤 맥락으로 전달될 것인가?”, “데이터 양이 늘어났을 때도 이 구조가 유효한가?”를 함께 고려하며 설계를 해야겠다. 그것이 개발자가 기여할 수 있는 데이터 엔지니어링의 시작점일 것이다.