[SAN] 프로젝트 회고
비동기 파이프라인과 벡터 검색을 직접 설계하고 구현한 4주간의 SAN 프로젝트 회고. 발표 직전 OpenAI 토큰 소진 사고와 경합 조건 트러블슈팅, 그리고 레이어 단위 테스트와 시스템 통합 테스트의 차이에 대해 기록합니다.
1. 프로젝트 개요
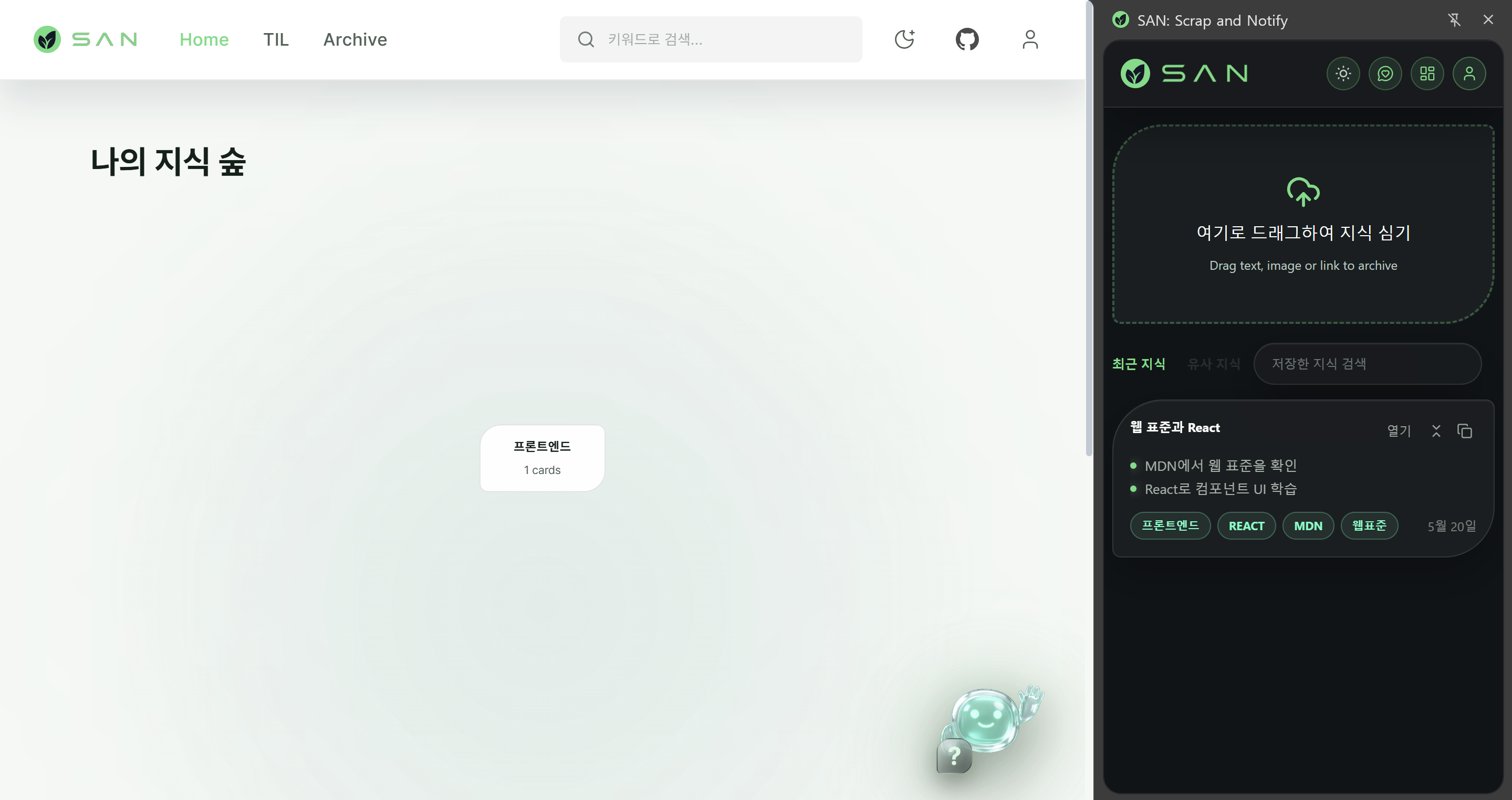
SAN(Scrap and Notify)은 사용자가 학습 내용을 스크랩하면 AI가 자동으로 지식 카드를 생성하고, TIL(Today I Learned) 요약과 리콜 퀴즈까지 이어주는 학습 관리 플랫폼입니다.
백엔드는 Spring Boot + PostgreSQL(pgvector) + FastAPI(AI 서버) 구성이며, 약 4주간 비동기 파이프라인 설계, 배치 스케줄러, 벡터 검색 엔진을 담당했습니다.
2. 주요 구현
비동기 파이프라인
사용자 요청 처리 흐름과 AI 서버 통신을 완전히 분리하는 것이 목표였습니다. Tomcat 스레드가 AI 응답을 기다리며 블로킹되면 동시 요청 처리 자체가 어렵기 때문입니다.
채택한 구조는 Spring Event + @Async + @TransactionalEventListener(AFTER_COMMIT) 조합입니다.
1
2
3
4
5
6
7
8
[메인 스레드]
scraps 저장 + async_jobs(PENDING) 생성
→ 202 즉시 반환
→ 트랜잭션 커밋 후 이벤트 발행
[비동기 워커 스레드]
이벤트 수신
→ PROCESSING 전환 → AI 호출 → COMPLETED/FAILED 전환
커밋 이후에 이벤트를 발행하는 이유는 롤백이 발생했을 때 존재하지 않는 데이터를 워커가 처리하는 상황을 막기 위해서입니다.
async_jobs 테이블의 status 컬럼이 모든 비동기 작업의 생명주기를 추적하는 중심축입니다. target_id는 FK 없이 소프트 참조로 설계했는데, 작업 종류(job_type)에 따라 가리키는 테이블이 달라 단일 FK로 표현할 수 없기 때문입니다.
신뢰성 보완을 위해 배치 스케줄러를 구성했습니다. 이벤트 유실이나 워커 중단으로 발생하는 유령 잡을 2시간 주기로 FAILED 후 재등록하고, 고아 스크랩을 복구하며, 매일 새벽 3시에 전날 학습한 사용자에게 TIL을 자동 생성합니다. HTTP 레벨 재시도(@Retryable, 최대 3회, 지수 백오프 2s→4s)와 잡 레벨 배치 재시도를 이중으로 구성해 일시적 장애와 영구 실패를 각각 다른 계층에서 처리했습니다.
벡터 검색 (pgvector 기반)
세 가지 검색 API를 구현했습니다.
| API | 임베딩 출처 | 특이사항 |
|---|---|---|
자연어 통합 검색 GET /api/search | AI 서버 (keyword → vector) | ILIKE 병합 Hybrid, 태그·날짜 필터, 페이지네이션 |
카드 기반 연관 추천 GET /api/cards/jobs/{jobId}/similar-cards | DB (카드 embedding) | 자기 자신 제외 후 3개 반환 |
TIL 기반 리콜 카드 GET /api/til/{summaryId}/recall-cards | DB (TIL embedding) | threshold(코사인 거리 < 0.3) 기반, 개수 제한 없음 |
리콜 카드 검색에서 개별 지식 카드가 아닌 TIL 요약 전체의 임베딩을 쿼리로 사용하는 것이 핵심 결정입니다. 오늘 학습한 내용의 거시적 문맥 벡터로 과거 카드를 연결하면 파편화 없이 연관성 있는 카드를 찾을 수 있습니다.
3. 트러블슈팅
발표 직전 OpenAI 토큰 소진
발표 전날 밤 OpenAI API 사용량이 급격히 치솟으며 토큰이 빠르게 소진됐습니다. 배치 스케줄러와 재시도 로직의 의도치 않은 상호작용이 원인이었습니다.
- AI 서버 응답이 느려지며 TIL 생성 요청이 타임아웃으로 실패
@Retryable이 즉시 3회 재시도, 모두 실패하며FAILED전환FailedJobRecoveryService가 FAILED 잡을 감지해 새 잡을 enqueue- 재등록된 잡도 타임아웃 → FAILED → enqueue 사이클 반복
MAX_RETRY_COUNT(3)가드의 카운팅 버그로 차단 실패- 동일 TIL에 대해 수십 번의 OpenAI 호출 발생
즉각 대응은 @Scheduled를 임시 비활성화하고 재시작해 추가 소진을 막는 것이었습니다.
근본 원인은 시스템 전체 관점의 피드백 루프 검증 부재였습니다. HTTP 재시도, 잡 레벨 재시도, 복구 스케줄러 각각은 단위 테스트를 통과했지만, 세 레이어가 동시에 동작하는 시나리오 (특히 AI 서버가 장애가 아닌 지연 상태일 때)를 사전에 검증하지 않았습니다.
사후 대책 방향:
- 스케줄러가 enqueue 전 AI 서버 헬스체크 선행
- 동일
(targetId, jobType)조합 잡 생성에 쿨다운 적용 MAX_RETRY_COUNT카운팅 로직 버그 수정 및 테스트 보강
비동기 중복 잡 경합 조건 (Race Condition)
TIL 생성 요청이 짧은 간격으로 중복 들어올 때 async_jobs에 동일한 작업이 두 개 생성되는 버그가 있었습니다. 애플리케이션 코드에서 중복 체크를 하고 있었는데도 막히지 않았습니다.
원인은 PostgreSQL 기본 격리 수준인 READ COMMITTED에서 발생하는 경합 조건이었습니다.
1
2
3
4
5
6
[요청 A] [요청 B]
중복 체크 → 없음
save(PENDING) ──────────────▶ 중복 체크
A의 미커밋 PENDING 안 보임
→ 중복 등록 (버그)
commit
existsByTargetIdAndJobTypeAndStatusIn은 커밋된 행만 읽습니다. A가 커밋하기 전에 B가 체크하면 PENDING 잡이 보이지 않아 중복이 통과됩니다. 애플리케이션 레벨의 check-then-insert 패턴은 이 문제를 본질적으로 해결할 수 없습니다.
daily_summaries에 SELECT FOR UPDATE를 걸어 동시 요청을 직렬화하는 방식으로 임시 해결했으나, 중복 방지 책임이 다른 도메인 테이블의 잠금에 의존하는 구조였고 다른 JobType이 추가될 경우 무관한 작업끼리 블로킹이 발생하는 문제가 있었습니다.
최종 해결은 async_jobs에 부분 유니크 인덱스를 직접 거는 것이었습니다.
1
2
3
CREATE UNIQUE INDEX IF NOT EXISTS uk_async_jobs_active_target_job_type
ON async_jobs (target_id, job_type)
WHERE status IN ('PENDING', 'PROCESSING');
active 상태인 동일 작업이 하나만 존재할 수 있다는 불변 조건을 DB가 직접 강제합니다. 어떤 경합 조건에서도 하나만 살아남습니다.
JPA @Table(indexes = ...)는 WHERE 절이 있는 부분 인덱스를 지원하지 않고, init 스크립트는 JPA ddl-auto보다 먼저 실행되어 테이블이 없는 문제가 있었습니다. Flyway는 단일 인덱스를 위해 도입하기엔 부담이 컸습니다. 최종적으로 ApplicationRunner + JdbcTemplate으로 앱 시작 시 IF NOT EXISTS로 멱등하게 생성하는 방식을 채택했습니다.
CGLIB 프록시 문제로 기동 실패
비동기 파이프라인을 처음 연결했을 때 애플리케이션이 기동조차 되지 않았습니다.
AsyncJobProcessor 인터페이스를 구현한 클래스에 @Async를 적용하면 Spring이 JDK 동적 프록시를 생성합니다. JDK 프록시는 인터페이스에 선언된 메서드만 노출하는데, @TransactionalEventListener가 붙은 handle() 메서드는 인터페이스에 없었습니다. @Async(프록시를 통해 호출 필요)와 @TransactionalEventListener(프록시에서 메서드 탐색 필요)가 동시에 붙은 메서드를 JDK 프록시가 처리할 수 없는 구조였습니다.
AsyncConfig에 @EnableAsync(proxyTargetClass = true) 한 줄로 해결했습니다. CGLIB는 인터페이스가 아닌 클래스 자체를 상속해 프록시를 만들기 때문에 인터페이스에 없는 메서드도 정상 노출됩니다.
4. 회고
잘한 점
비동기 파이프라인을 가볍게 구현하면서 핵심 개념을 제대로 익혔습니다. Spring Event + @Async 조합은 외부 메시지 큐 없이 JVM 내부에서 메시지 버스 개념을 구현하는 방식입니다. 메시지 큐를 쓰지 않은 대신 이벤트 유실 가능성을 배치 스케줄러로 보완하는 트레이드오프를 의식적으로 선택했고, 덕분에 메시지 버스, 스레드 풀, 트랜잭션 커밋 타이밍 같은 개념을 코드로 직접 다루면서 깊이 이해하게 됐습니다.
관찰 가능성을 처음부터 설계에 넣었습니다. 동기 API는 에러가 즉시 응답으로 옵니다. 비동기는 조용히 실패합니다. async_jobs에 error_message를 저장한 덕분에 장애 원인을 job_id 하나로 추적할 수 있었습니다. 발표 직전 토큰 소진 사고 때도 어떤 잡이 몇 번 실패했는지 쿼리 한 줄로 파악할 수 있었던 게 빠른 대응에 도움이 됐습니다.
설계 결정을 그때그때 문서로 남겼습니다. Spring Event vs DB 폴링, JDK 프록시 vs CGLIB, target_id에 FK를 안 건 이유까지, 결정을 내릴 때마다 기록을 남겼습니다. 이 회고도 그 기록들이 없었으면 쓰기 훨씬 힘들었을 것입니다.
아쉬운 점
레이어별 정상 동작과 시스템 전체 정상 동작은 다릅니다. @Retryable, 배치 재시도, 복구 스케줄러 각각은 단위 테스트를 통과했습니다. 하지만 세 레이어가 동시에 동작하는 시나리오, 특히 외부 AI 서버가 느릴 때의 피드백 루프는 검증하지 않았습니다. 토큰 소진 사고는 이 빈틈에서 발생했습니다. 컴포넌트 단위 테스트만큼 시스템 통합 관점의 시나리오 검증이 중요하다는 것을 뼈저리게 느꼈습니다.
사용자 피드백을 받지 못하고 끝났습니다. 프론트 인력 부족과 크롬 익스텐션 스토어 등록 승인 지연으로 결국 발표 시연에만 그쳤습니다. 열심히 만든 비동기 파이프라인과 벡터 검색이 실제 사용자 트래픽을 한 번도 받아보지 못한 채 마무리된 게 가장 아쉽습니다. 한편으로는, 실제 유저를 받았다면 토큰은 훨씬 더 빨리 동났겠다 싶기도 합니다.
 Chrome 웹 스토어 게시
Chrome 웹 스토어 게시
다음에는
외부 의존성이 있는 배치 작업에는 서킷 브레이커나 헬스체크가 필요합니다. 이번 사고의 핵심은 AI 서버가 느려진 상태에서 스케줄러가 계속 잡을 밀어넣었다는 것입니다. 다음에는 배치 실행 전 외부 서비스 헬스체크를 선행하거나, 연속 실패가 임계치를 넘으면 일시 중단하는 서킷 브레이커 패턴을 적용할 것입니다.
메시지 큐 도입을 진지하게 고려할 것입니다. JVM 내부 이벤트 버스는 서버 재시작 시 큐에 쌓인 이벤트가 소멸하는 근본적인 한계가 있습니다. 이번에 배치 복구 스케줄러로 이 한계를 보완했지만, 트래픽이 늘거나 멀티 인스턴스 환경이 되면 Redis Stream이나 Kafka 도입이 불가피합니다. 내부 이벤트 버스로 개념을 확실히 익혔으니, 다음에는 외부 메시지 큐로 동일한 구조를 구현해보고 싶습니다.