[SAN] 리콜 카드 조회 설계: 저장 vs 실시간, 추출 기준, ERD 의사결정
TIL 페이지 하단 리콜 카드 목록을 설계하면서 생긴 의문점들 — DB 저장 vs 실시간 조회, 어떤 임베딩 기준으로 추출할지, 임베딩 테이블 분리 안티패턴, NULL 허용 여부 — 의사결정 과정을 기록합니다.
TIL 페이지는 당일 스크랩한 지식 카드 원본 데이터를 요약한 TIL 내용과 리콜 카드를 제공합니다. TIL은 다음날 아침 알림으로 접근하거나, 당일 ‘생성하기’ 버튼으로 접근할 수 있으며, 이전 날짜 TIL 페이지도 확인 가능합니다.
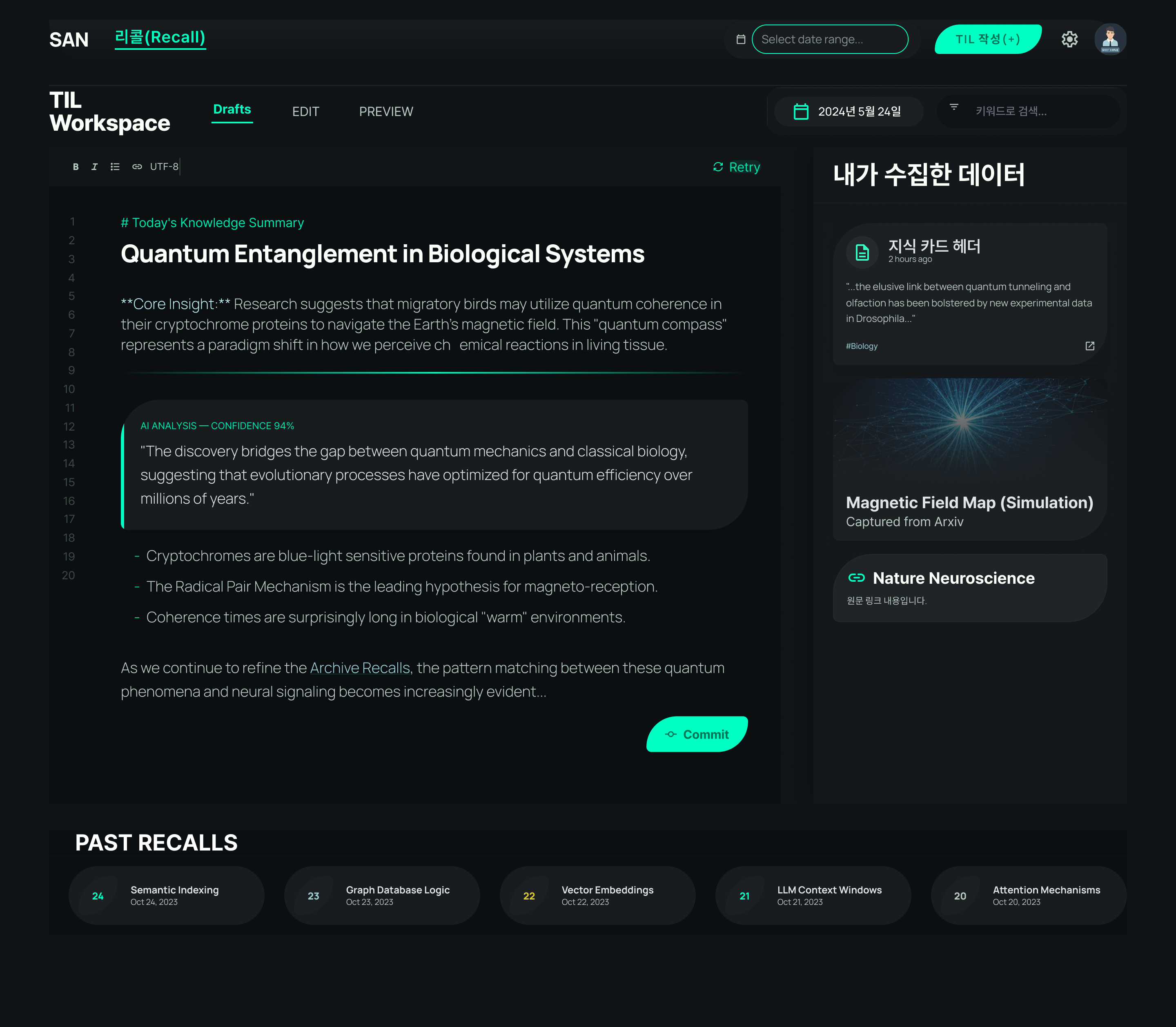 TIL 페이지 프로토타입
TIL 페이지 프로토타입
TIL 페이지 하단에는 오늘의 학습 내용과 연관된 과거 지식 카드 목록(리콜 카드)이 노출됩니다. 이 목록을 어떻게 구성하고 조회할지 설계하는 과정에서 다음 두 가지 의문이 생겼습니다.
1. 리콜 카드 목록을 DB에 저장해둘까, 실시간 조회할까?
UX를 고려했을 때, 리콜 카드 목록을 DB에 저장해두는 것이 나을까? 다른 날짜 TIL 페이지를 볼 때 로딩 없이 출력할 수 있지만, 지식 카드가 추가되면 전체 목록을 갱신해야 하거나 실시간성이 떨어질 수 있을 것 같다.
실시간 조회를 선택합니다. 이유는 세 가지입니다.
데이터 신선도: 사용자가 아침에 TIL을 확인하고 오후에 새로운 지식 카드를 추가했다면, 리콜 목록을 미리 저장해뒀을 경우 오후에 추가된 카드는 오늘자 TIL의 연관 카드에 노출되지 않습니다. 실시간 조회를 하면 지식이 늘어날수록 과거 TIL 페이지의 연관 카드도 점점 풍부해집니다.
pgvector 성능: LIKE나 복잡한 JOIN과 달리, pgvector는 HNSW 인덱스를 활용하면 수만 건의 벡터에서 코사인 유사도 기반 Top-K를 수십 밀리초 안에 처리합니다. UX를 해칠 만한 로딩 지연이 발생하지 않습니다.
유지보수 비용: 연관 관계 테이블을 따로 두면 데이터 삭제·수정 시마다 연쇄적인 DB I/O 처리가 필요합니다.
2. 리콜 카드를 어떤 기준으로 추출할까?
리콜 카드 목록을 조회할 때 어떤 기준으로 잘라야 할까? ① 개별 지식 카드에 대한 리콜 카드 K개를 불러와 합쳐서 출력한다. ② 개별 지식 카드에 대한 리콜 카드 목록을 불러와 유사도 높은 순 TOP-K를 자른다. ③ TIL 요약에 대한 임베딩을 기준으로 리콜 카드 N개를 불러온다.
세 가지 방법 중 ③번(TIL 요약 임베딩 기준 N개)을 선택합니다.
①번과 ②번은 오늘 수집한 카드 수만큼 벡터 DB에 쿼리를 반복 호출해야 합니다. 카드가 10장이면 10번입니다.
③번은 TIL 생성 시 만들어진 요약본 하나의 임베딩 벡터로 단 1번의 쿼리만 날립니다. 여러 카드를 종합한 TIL 요약이 “오늘의 맥락 벡터” 역할을 하기 때문에, 개별 카드 기준보다 문맥 차원에서 더 일관성 있는 리콜 카드가 추출됩니다. 오늘 스크랩한 카드가 ‘Celery 비동기’, ‘RabbitMQ 개념’, ‘FastAPI 라우터’라면 개별 기준으로는 파편화된 결과가 나오지만, TIL 요약 임베딩은 “Python 비동기 메시지 큐 아키텍처”라는 거시적인 맥락 벡터가 됩니다.
3. 임베딩 테이블 분리는 pgvector에서 안티패턴
현재 DB에는 임베딩 테이블이 별도로 있고, 지식 카드(Knowledge_cards)와 임베딩의 매핑 테이블, TIL(daily_summaries)과 임베딩의 매핑 테이블이 각각 생성되어 있다.
현재 스키마는 임베딩을 별도 테이블로 분리하고 매핑 테이블을 두고 있는데, 이 구조는 pgvector 환경에서 성능 병목을 유발합니다.
1
2
3
4
5
6
7
8
-- 현재 구조 (수정 필요): JOIN 연산으로 벡터 검색 속도 저하
knowledge_cards (id, title, summary)
embeddings (id, vector_data)
card_embedding_mappings (card_id, embedding_id)
-- 변경 구조 (pgvector 권장): 단일 테이블에서 한 번에 연산
knowledge_cards (id, title, summary, embedding vector(1536))
daily_recalls (id, target_date, daily_markdown, embedding vector(1536))
엔티티 테이블에 vector 타입 컬럼을 직접 두면, 유사도 계산(<=>)과 권한 필터링(WHERE user_id = ?)을 단 1번의 쿼리로 처리할 수 있습니다. TIL 생성 시 요약본의 임베딩을 daily_recalls.embedding에 저장해두고, 프론트에서 TIL 페이지를 열 때 그 벡터로 knowledge_cards를 검색하는 흐름입니다.
embedding 컬럼은 NULL 허용인가?
“지식 카드라면 당연히 벡터 값이 있어야 한다”고 생각해 NOT NULL을 걸고 싶지만, AI API를 연동하는 비동기 환경에서는 NULL을 허용해야 합니다.
부분 실패 대응: AI 파이프라인은 ① LLM 요약 → ② 임베딩 변환의 두 단계로 진행됩니다. 요약은 성공했는데 임베딩 API 호출에서 타임아웃이 발생했다면, NOT NULL이면 INSERT 자체가 실패해 요약 데이터까지 날아갑니다. NULL 허용이면 텍스트 데이터라도 먼저 저장하고, 스케줄러나 재시도 로직으로 비어있는 임베딩 컬럼만 나중에 채울 수 있습니다.
지연 생성 아키텍처 지원: 현재는 “요약 + 임베딩”을 한 번에 처리하지만, 서비스가 커지면 “텍스트는 즉시 보여주고, 임베딩은 배치로 야간에 처리하자”는 방향으로 바뀔 수 있습니다. NULL 허용이면 스키마 변경 없이 수용 가능합니다.
수동 작성 데이터 확장성: 사용자가 AI를 거치지 않고 직접 지식 카드를 입력하는 기능이 추가될 경우, 저장 시점에 임베딩 벡터가 없으므로 NULL 허용이 필수입니다.
NULL 허용 시 벡터 검색 쿼리 주의사항
임베딩이 NULL인 카드와 코사인 거리를 계산하면 에러가 발생합니다. 벡터 검색 쿼리에 반드시 IS NOT NULL 조건을 추가해야 합니다.
1
2
3
4
5
6
7
8
9
10
11
SELECT
id,
title,
summary,
(embedding <=> CAST(:queryVector AS vector)) AS distance
FROM knowledge_cards
WHERE user_id = :userId
AND is_deleted = false
AND embedding IS NOT NULL
ORDER BY distance ASC
LIMIT :k;
엔티티 컬럼은 느슨하게(Nullable) 열어두고, 쿼리 단에서 엄격하게 필터링하는 구조입니다.
마치며
최종적으로 정돈된 전체 데이터 흐름은 다음과 같습니다.
1
2
3
4
5
6
7
텍스트 / 검색어 / 카드 내용
→ AI 서버: 임베딩 벡터 생성
→ 백엔드: 벡터 DB에 유사도 검색 요청
→ pgvector: 코사인 거리 계산
→ 유사한 cardId 목록 반환
→ 백엔드: RDB에서 카드 상세 조회
→ 프론트엔드: 결과 반환