[SAN] 비동기 작업 DB 설계
async_jobs 단일 테이블로 여러 비동기 작업을 관리하는 DB 설계를 기록합니다. target_id에 FK를 걸지 않은 이유(다형적 연관관계), error_message를 파일 로그 대신 DB에 저장하는 이유를 중심으로 정리합니다.
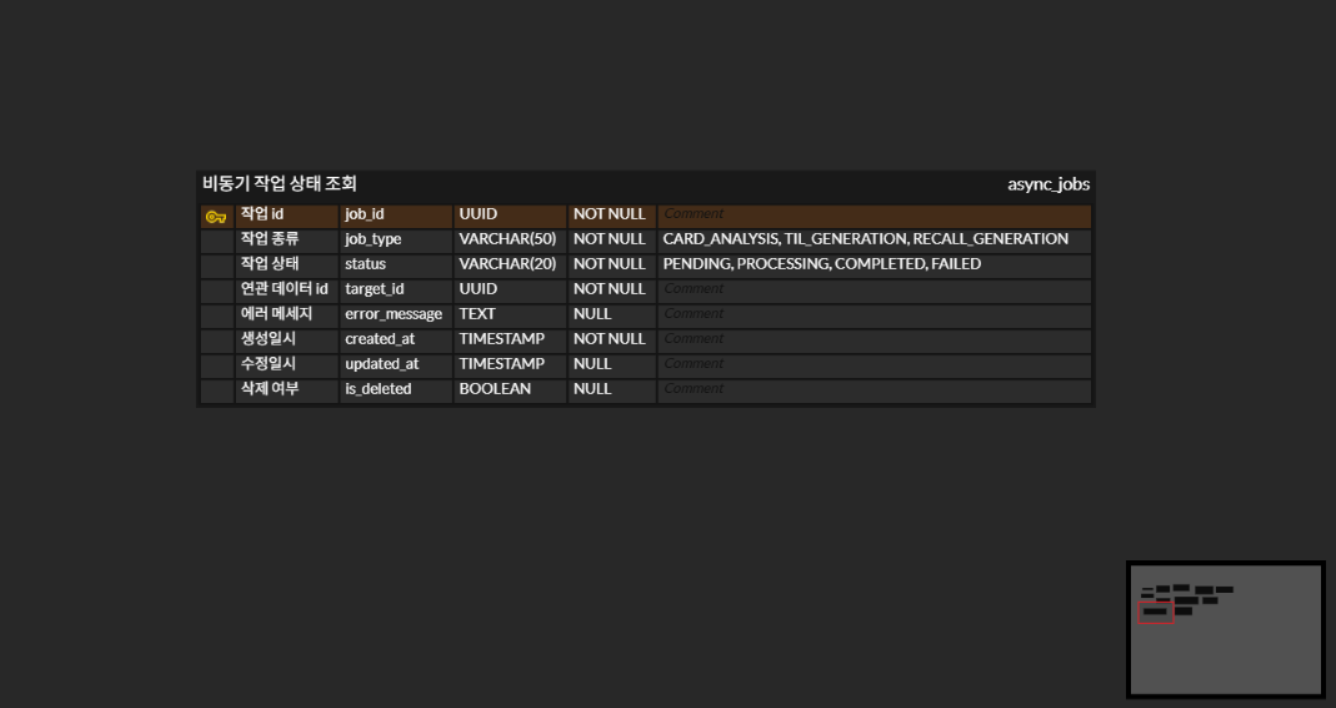
SAN(Scrap & Notify)의 비동기 작업은 async_jobs 테이블 하나로 관리합니다. 설계 과정에서 target_id에 FK를 걸지 않은 이유, error_message를 어디에 어떤 형태로 저장할지 두 가지 의문이 생겼습니다.
async_jobs 테이블
1
2
3
4
5
6
async_jobs
├── id (UUID, PK)
├── job_type -- CARD_ANALYSIS | TIL_GENERATION | RECALL_GENERATION
├── status -- PENDING | PROCESSING | COMPLETED | FAILED
├── target_id -- 연관 대상 식별자 (FK 없음, soft reference)
└── error_message -- 실패 시 에러 원인 추적용
작업 상태는 생성부터 완료까지 다음 방향으로 전이됩니다.
1
2
PENDING → PROCESSING → COMPLETED
↘ FAILED
 async_jobs DB 테이블
async_jobs DB 테이블
target_id를 FK로 하지 않은 이유는?
처음에는 “작업이 2개 이상일 수도 있어서”로 생각했지만, 하나의 컬럼이 서로 다른 여러 테이블을 가리켜야 하기 때문(다형성, Polymorphic Association)입니다.
target_id는 job_type에 따라 가리키는 테이블이 달라집니다.
CARD_ANALYSIS→scraps.idTIL_GENERATION→daily_summarys.id(또는 날짜)RECALL_GENERATION→daily_summarys.id
RDBMS의 FK는 단일 테이블만 지정할 수 있습니다. 이 구조에 FK를 걸려면 작업 타입마다 별도 컬럼(scrap_id, daily_recall_id, …)을 추가해야 합니다. 새로운 비동기 작업 타입이 생길 때마다 async_jobs 테이블에 컬럼을 추가해야 하는 안티 패턴입니다.
대신 UUID 값만 저장하는 소프트 참조(Soft Reference), 즉 다형적 연관관계(Polymorphic Association) 방식을 택했습니다. async_jobs 스키마 변경 없이 새로운 작업 타입을 추가할 수 있고, 도메인 테이블(scraps 등)과 시스템 테이블(async_jobs)의 생명주기가 물리적으로 분리됩니다.
각 작업을 담당하는 AsyncJobProcessor 구현체 안에서 target_id로 직접 조회합니다. JPA의 @ManyToOne 매핑 대신 ScrapRepository.findById(targetId)를 명시적으로 호출하는 방식입니다.
target_id가 NOT NULL이어야 하는 이유
현재 정의된 모든 작업은 반드시 대상이 존재합니다.
CARD_ANALYSIS: 어떤 스크랩을 분석할 것인가?TIL_GENERATION: 어떤 사용자나 날짜의 데이터를 요약할 것인가?
NOT NULL 제약은 DB 레벨에서 대상 식별자 없이 작업이 생성되는 실수를 즉시 차단합니다. NOT NULL 컬럼은 인덱싱 효율도 더 좋고 쿼리 작성이 간결해집니다.
FK가 없는데 대상이 삭제되면?
NOT NULL은 저장 시점에 값이 있는지를 보장할 뿐, 그 값이 가리키는 대상이 실제로 존재하는지는 실시간으로 보장하지 않습니다. 워커 실행 전에 사용자가 원본을 삭제한 경우, 워커 시작 시 첫 번째로 target_id로 조회를 시도하고 데이터가 없으면 FAILED로 기록하고 종료합니다.
1
2
3
4
5
Optional<Scrap> scrap = scrapRepository.findById(job.getTargetId());
if (scrap.isEmpty()) {
job.markAsFailed("Target data not found (Already deleted)");
return;
}
error_message를 DB에 저장하는 이유?
비동기 작업은 실패해도 화면에 에러 트레이스가 즉각 나타나지 않습니다(silent fail). 파일 로그만 있으면 실패 원인을 찾기 위해 수천 줄의 로그를 시간대별로 뒤져야 합니다.
target_id와 함께 error_message가 DB에 있으면 “어떤 스크랩을 처리하다가, 왜 실패했는지”를 즉시 파악할 수 있습니다.
타겟 추적: 파일 로그만으로는 수천 개의 스크랩 중 어떤 스크랩을 처리하다가 에러가 난 건지 맥락을 찾기 어렵습니다. DB에 target_id와 함께 기록되어 있으면 즉시 파악할 수 있습니다.
수동 복구: AI 서버가 10분간 다운되어 수백 건이 실패했다면, 파일 로그만 있으면 실패한 ID를 정규식으로 일일이 뽑아내야 합니다. DB에 있으면 쿼리 하나로 대상 목록을 추출해 일괄 재시도할 수 있습니다.
1
2
SELECT target_id FROM async_jobs
WHERE status = 'FAILED' AND error_message LIKE '%Timeout%';
CS 대응: 프론트엔드가 status: FAILED를 받아 “오류 번호: {job_id}”를 사용자에게 안내하면, 개발자는 그 job_id만 조회해 실패 원인을 즉시 파악할 수 있습니다.
error_code가 아닌 error_message 전문이 중요한 이유
동기 API에서는 ErrorCode.AI_TIMEOUT처럼 규격화된 코드가 맞습니다. 프론트엔드가 그 코드를 보고 사용자에게 적절한 메시지를 보여줄 수 있기 때문입니다. 하지만 비동기 백그라운드 작업의 실패 기록은 백엔드 개발자의 디버깅을 위한 것입니다. 성격이 다릅니다.
AI 서버 실패 사유는 사전에 정의하기 어렵습니다.
- “Rate Limit Exceeded (Too many requests)”
- “Token limit exceeded (8500 > 8192)”
- “JSON Parse Error at line 4”
이런 구체적인 사유들을 error_code 몇 개로 미리 정의하는 것은 현실적이지 않습니다. 비동기 작업은 에러가 나도 화면에 바로 표시되지 않고 조용히 실패하기 때문에, DB에 AI_ERROR라는 코드만 남아있으면 개발자는 방대한 서버 로그를 시간대별로 뒤져야 합니다.
errorCode + errorTrace 조합은 어떨까
넓은 카테고리 수준(5~6개)의 errorCode와 상세 원인을 담는 errorTrace를 함께 쓰는 방법도 검토했습니다.
1
2
3
errorCode = AI_COMMUNICATION_FAILED ← 넓은 분류
errorTrace = "WebClientResponseException: 429 Too Many Requests
caused by: Rate limit exceeded (8500 > 8192)"
WHERE error_code = 'AI_COMMUNICATION_FAILED' 같은 쿼리 필터링이 가능하다는 장점이 있습니다. 그러나 현재 프로젝트 규모에서 에러를 코드로 분류해 집계·필터링할 요구사항이 없었기 때문에, 필드를 추가하는 복잡도 대비 실익이 없었습니다.
cause chain만 추출해서 저장
Java의 전체 스택트레이스를 그대로 저장하면 건당 수십~수백 줄에 달합니다. 실제 가치 있는 정보는 첫 줄과 Caused by 체인뿐이고, 전체 트레이스는 Logback 서버 로그에 남으므로, DB에는 cause chain만 추출해서 저장하는 것이 실용적입니다.
1
2
3
BusinessException: AI 분석 요청에 실패했습니다.
caused by: WebClientResponseException$TooManyRequests: 429 Too Many Requests
caused by: reactor.core.Exceptions: Rate limit exceeded
errorMessage필드에 cause chain을 순회해 추출한 메시지를 저장errorCode필드는 추가하지 않음 — cause chain 메시지 자체로 원인 파악이 가능- 별도
errorTrace필드도 추가하지 않음 (오버엔지니어링)
cause chain 순회 로직은 AsyncJobProcessor 인터페이스의 default 메서드 resolveErrorMessage(e, fallback)로 공통화해 구현체마다 중복 작성하지 않도록 했습니다.