[SAN] 비동기 작업 파이프라인 설계
Kafka 없이 Spring Boot의 ApplicationEventPublisher와 @Async, 단일 테이블로 비동기 파이프라인을 구축한 과정을 기록합니다. target_id 소프트 참조와 error_message DB 저장을 선택한 설계 이유를 중심으로 정리합니다.
SAN(Scrap & Notify)은 스크랩한 콘텐츠를 AI로 분석해 지식 카드를 생성하고, 리콜 기능으로 관련 내용을 다시 꺼내 쓰는 프로젝트입니다. AI 요약과 벡터 임베딩 생성은 수 초가 걸리는 작업이라 동기 응답으로 처리할 수 없습니다. MVP 단계에서는 Kafka나 RabbitMQ 같은 외부 메시지 큐 없이, Spring Boot의 ApplicationEventPublisher와 @Async, 그리고 단일 테이블 하나로 비동기 파이프라인을 구축했습니다.
async_jobs 테이블
1
2
3
4
5
6
async_jobs
├── id (UUID, PK)
├── job_type -- CARD_ANALYSIS | TIL_GENERATION | RECALL_GENERATION
├── status -- PENDING | PROCESSING | COMPLETED | FAILED
├── target_id -- 연관 대상 식별자 (FK 없음, soft reference)
└── error_message -- 실패 시 에러 원인 추적용
작업 상태는 생성부터 완료까지 다음 방향으로 전이됩니다.
1
2
PENDING → PROCESSING → COMPLETED
↘ FAILED
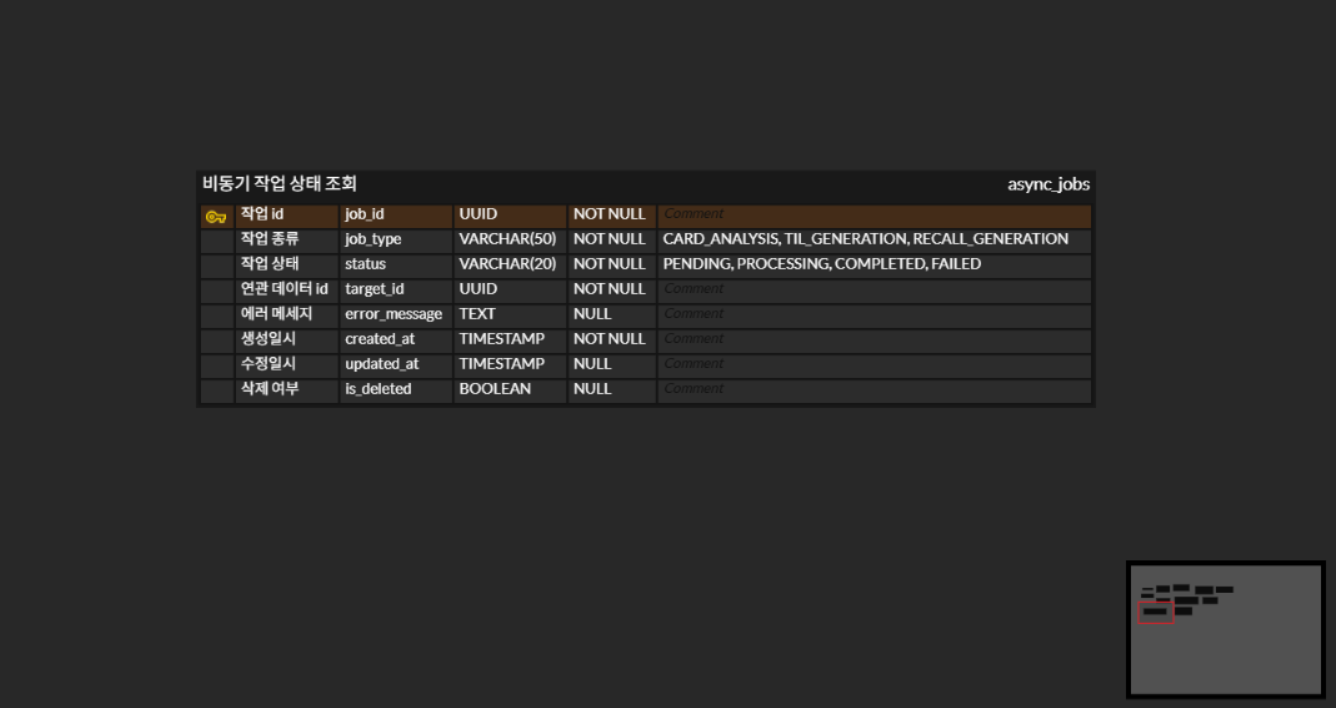 async_jobs DB 테이블
async_jobs DB 테이블
파이프라인 흐름
지식 카드 생성(CARD_ANALYSIS)을 기준으로 세 단계로 진행됩니다.
1단계: 동기 응답 (메인 스레드)
사용자가 스크랩을 요청하면 메인 스레드는 원본 데이터를 scraps 테이블에 저장하고, async_jobs에 PENDING 상태로 작업을 생성합니다. 즉시 200 OK와 job_id를 반환해 사용자 대기를 풀고, 내부적으로 JobCreatedEvent를 발행합니다.
2단계: 비동기 처리 (워커 스레드)
@EventListener가 이벤트를 감지하면 @Async 스레드 풀에서 워커 스레드가 실행됩니다. 작업을 집어 들 때 상태를 PROCESSING으로 변경한 뒤, AI 서버(FastAPI)에 원문을 보내 요약·태그·벡터 임베딩을 요청합니다. 응답을 받아 knowledge_cards에 적재하면 COMPLETED로 전환하고 종료합니다. 예외가 발생하면 FAILED로 기록합니다.
3단계: 상태 확인 (클라이언트 폴링)
프론트엔드는 받은 job_id로 GET /api/jobs/{jobId}를 1~2초 주기로 호출해 완료 여부를 확인합니다.
상태 변경 주체를 정리하면 다음과 같습니다.
| 상태 | 변경 주체 | 시점 |
|---|---|---|
PENDING | 메인 스레드 | 작업 생성 시 (기본값) |
PROCESSING | 비동기 워커 스레드 | AI 요청 직전 |
COMPLETED | 비동기 워커 스레드 | DB 적재 완료 후 |
FAILED | 비동기 워커 스레드 | 예외 발생 시 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
// [메인 스레드] ScrapService.java
@Transactional
public ScrapResponse createScrap(ScrapRequest request) {
Scrap scrap = scrapRepository.save(new Scrap(request));
AsyncJob job = AsyncJob.builder()
.jobType(JobType.CARD_ANALYSIS)
.targetId(scrap.getId())
.build(); // 기본값 PENDING
asyncJobRepository.save(job);
eventPublisher.publishEvent(new JobCreatedEvent(job.getId()));
return new ScrapResponse(scrap.getId(), job.getId());
}
// [비동기 워커 스레드] CardAnalysisProcessor.java
@Async
@EventListener
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void handleCardAnalysis(JobCreatedEvent event) {
AsyncJob job = asyncJobRepository.findById(event.getJobId()).orElseThrow();
try {
job.markAsProcessing();
asyncJobRepository.saveAndFlush(job);
aiClient.analyze(job.getTargetId());
job.markAsCompleted();
} catch (Exception e) {
String message = e.getMessage();
if (message != null && message.length() > 1000) {
message = message.substring(0, 1000) + "...";
}
job.markAsFailed(message);
log.error("[AsyncJob Failed] JobId: {}, Reason: {}", job.getId(), e.getMessage(), e);
} finally {
asyncJobRepository.save(job);
}
}
워커 트랜잭션에 Propagation.REQUIRES_NEW를 사용하는 이유는 메인 스레드의 트랜잭션과 분리하기 위해서입니다. 같은 트랜잭션 안에서 실행되면 PROCESSING 상태 변경이 메인 커밋 전까지 DB에 반영되지 않아 폴링 시 정합성 문제가 생깁니다.
target_id를 FK로 하지 않은 이유는?
처음에는 “작업이 2개 이상일 수도 있어서”로 생각했지만, 하나의 컬럼이 서로 다른 여러 테이블을 가리켜야 하기 때문(다형성, Polymorphic Association)입니다.
target_id는 job_type에 따라 가리키는 테이블이 달라집니다.
CARD_ANALYSIS→scraps.idTIL_GENERATION→daily_summarys.id(또는 날짜)RECALL_GENERATION→daily_summarys.id
RDBMS의 FK는 단일 테이블만 지정할 수 있습니다. 이 구조에 FK를 걸려면 작업 타입마다 별도 컬럼(scrap_id, daily_recall_id, …)을 추가해야 합니다. 새로운 비동기 작업 타입이 생길 때마다 async_jobs 테이블에 컬럼을 추가해야 하는 안티 패턴입니다.
대신 UUID 값만 저장하는 소프트 참조(Soft Reference), 즉 다형적 연관관계(Polymorphic Association) 방식을 택했습니다. async_jobs 스키마 변경 없이 새로운 작업 타입을 추가할 수 있고, 도메인 테이블(scraps 등)과 시스템 테이블(async_jobs)의 생명주기가 물리적으로 분리됩니다.
각 작업을 담당하는 AsyncJobProcessor 구현체 안에서 target_id로 직접 조회합니다. JPA의 @ManyToOne 매핑 대신 ScrapRepository.findById(targetId)를 명시적으로 호출하는 방식입니다.
target_id가 NOT NULL이어야 하는 이유
현재 정의된 모든 작업은 반드시 대상이 존재합니다.
CARD_ANALYSIS: 어떤 스크랩을 분석할 것인가?TIL_GENERATION: 어떤 사용자나 날짜의 데이터를 요약할 것인가?
NOT NULL 제약은 DB 레벨에서 대상 식별자 없이 작업이 생성되는 실수를 즉시 차단합니다. NOT NULL 컬럼은 인덱싱 효율도 더 좋고 쿼리 작성이 간결해집니다.
FK가 없는데 대상이 삭제되면?
NOT NULL은 저장 시점에 값이 있는지를 보장할 뿐, 그 값이 가리키는 대상이 실제로 존재하는지는 실시간으로 보장하지 않습니다. 워커 실행 전에 사용자가 원본을 삭제한 경우, 워커 시작 시 첫 번째로 target_id로 조회를 시도하고 데이터가 없으면 FAILED로 기록하고 종료합니다.
1
2
3
4
5
Optional<Scrap> scrap = scrapRepository.findById(job.getTargetId());
if (scrap.isEmpty()) {
job.markAsFailed("Target data not found (Already deleted)");
return;
}
error_message를 DB에 저장하는 이유?
비동기 작업은 실패해도 화면에 에러 트레이스가 즉각 나타나지 않습니다(silent fail). 파일 로그만 있으면 실패 원인을 찾기 위해 수천 줄의 로그를 시간대별로 뒤져야 합니다.
target_id와 함께 error_message가 DB에 있으면 “어떤 스크랩을 처리하다가, 왜 실패했는지”를 즉시 파악할 수 있습니다.
파일 로그 대신 DB에 저장하는 이유
타겟 추적: 파일 로그만으로는 수천 개의 스크랩 중 어떤 스크랩을 처리하다가 에러가 난 건지 맥락을 찾기 어렵습니다. DB에 target_id와 함께 기록되어 있으면 즉시 파악할 수 있습니다.
수동 복구: AI 서버가 10분간 다운되어 수백 건이 실패했다면, 파일 로그만 있으면 실패한 ID를 정규식으로 일일이 뽑아내야 합니다. DB에 있으면 쿼리 하나로 대상 목록을 추출해 일괄 재시도할 수 있습니다.
1
2
SELECT target_id FROM async_jobs
WHERE status = 'FAILED' AND error_message LIKE '%Timeout%';
CS 대응: 프론트엔드가 status: FAILED를 받아 “오류 번호: {job_id}”를 사용자에게 안내하면, 개발자는 그 job_id만 조회해 실패 원인을 즉시 파악할 수 있습니다.
error_code가 아닌 error_message 전문이 중요한 이유
동기 API에서는 ErrorCode.AI_TIMEOUT처럼 규격화된 코드가 맞습니다. 하지만 비동기 백그라운드 작업의 실패는 백엔드 개발자의 디버깅을 위한 기록이어야 합니다.
AI 서버 실패 사유는 사전에 정의하기 어렵습니다.
- “Rate Limit Exceeded (Too many requests)”
- “Token limit exceeded (8500 > 8192)”
- “JSON Parse Error at line 4”
이런 구체적인 사유들을 error_code 몇 개로 미리 정의하는 것은 현실적이지 않습니다. 비동기 작업은 에러가 나도 화면에 바로 표시되지 않고 조용히 실패하기 때문에, DB에 AI_ERROR라는 코드만 남아있으면 개발자는 방대한 서버 로그를 시간대별로 뒤져야 합니다.
다만 Full Stack Trace를 그대로 저장하면 용량을 낭비하므로, 코드에서 보듯 1000자로 잘라 저장합니다.